


Ми впевнені, що серед наших клієнтів є багато професіоналів IT, які працюють над цікавими проектами. Якщо у Вас виникає бажання розповісти про них, Ви можете розмістити статтю у нашому блозі. А щоб було цікавіше, ми зробили конкурс статей, щомісяця три переможці отримуватимуть призи.
Стаття також доступна російською (перейти до перегляду).

Зміст:
- Основні відомості про Observability
- Реалізація Observability-системи
- Логування
- Збір метрик
- Трейсінг
- Профайлінг
- Алертінг та SLO/SLI
- Висновки
У класичних PHP?проєктах достатньо було APM?інструментів: вони показували час відповіді, помилки й «вузькі місця». Але зі зростанням мікросервісів, хмарної інфраструктури та короткоживучих процесів (функції, воркери, serverless) цей підхід втрачає ефективність. Дані розпорошені, залежності складні, а час на реакцію — мінімальний.
Observability відповідає на ці виклики: замість «виміряти кілька метрик» ми будуємо повну картину системи через логи, метрики, трейси та профайлинг. І цей підхід так само працює для моноліту, як і для складної розподіленої архітектури. Далі розберемося, як це реалізувати в PHP на практиці.
Основні відомості про Observability
Термін Observability став широко відомим з 60-х років минулого століття у зв’язку з публікацією інженером Кальманом наукової праці з теорії управління. Відповідно до визначеної автором концепції, вказаний термін є мірою того, наскільки легко можна визначити стан системи за її вихідними даними. Для галузі програмування термін має той самий зміст, але у якості вихідної інформації тут використовується набір телеметричних даних, основними з яких є наступні:
-
Метрики;
-
Журнали;
-
Трейси.
Observabilityphp ефективно «працює» лише при умові наявності достатньої кількості телеметричних даних, і чим їх більше, тим більш «прозорою» буде поведінка додатку. Це напряму впливає на час реагування розробників на виникаючі проблеми в його роботі та сприяє підвищенню ефективності розробки / супроводу.
Телеметричні дані збираються з ендпойнтів додатку та сервісів з різних джерел. Це реалізується шляхом виконання інструментації додатку, котра може бути нативною або зовнішньою. У першому випадку у «тіло» програми імплантується службовий код для генерування телеметричних даних. У другому випадку може бути застосована одна з технологій, наприклад, eBPF або sidecar. Після цього відбувається співставлення даних із різних джерел, їх аналіз та візуалізація.
Для хмарних середовищ зі складною архітектурою Observability повинна враховувати не лише «традиційні» телеметричні дані, котрі ми вже розглянули, але й багато інших (див. Малюнок 1):
-
Метадані;
-
Топологію та картографію мережі;
-
Інформацію на рівні коду;
-
Поведінку користувачів.
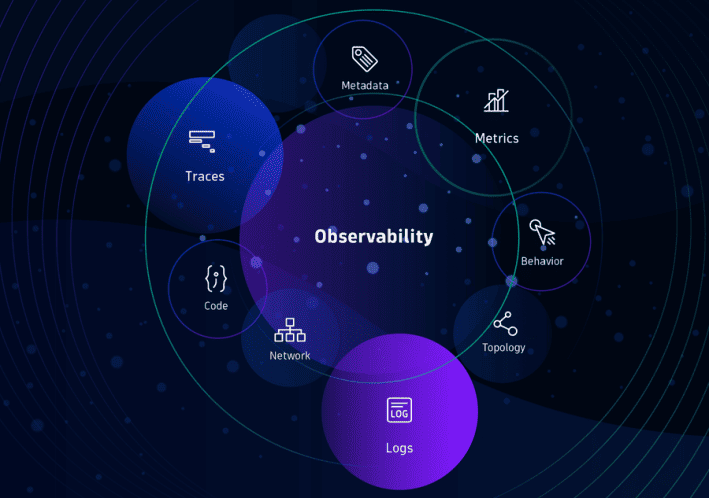
Малюнок 1. Набір телеметричних та інших даних для включення у Observability.
Ключовою відмінністю Observability від традиційного моніторингу є реалізація концепції «unknown unknowns», згідно якої під час процесу спостереження відбувається виявлення умов, котрі у більшості випадків заздалегідь невідомі розробникам. Після цього відслідковується їх зв’язок із визначеними проблемами продуктивності, що надає більш глибокий контекст для виявлення першопричини та пришвидшує вирішення проблеми.
Водночас, при традиційному моніторингу, навпаки, заздалегідь визначено, що саме треба шукати, тобто, тут працює принципово відмінна концепція «known unknowns», що дозволяє лише «отримати повідомлення» про перевищення критичних значень параметрів. Але причину цього знайти набагато важче.
Можна виділити наступні переваги нового підходу:
-
Можливість виявлення та усунення проблем на початкових етапах розробки;
-
Покращення користувацького досвіду;
-
Автоматизація усунення недоліків та самооновлення інфраструктури додатку при застосуванні ШІ;
-
Автоматичне масштабування;
-
Безпечний деплой;
-
Мінімізація середнього значення часу поновлення (MTTR - Mean Time To Resolve).
Реалізація Observability-системи
Сучасні системи спостереження зазвичай включають стек відомих платформ або технологій, кожна з яких може реалізовувати визначену функціональність. Наведемо основні з цих функцій:
-
Засоби інструментації коду додатку;
-
Збір, збереження та доставка телеметричних даних;
-
Розподілений бекенд трейсів;
-
Генератори Alert-повідомлень для клієнтів;
-
Засоби пошуку;
-
Кореляція роботи компонентів розподіленої системи;
-
Аналіз даних та їх візуалізація.
На ринку програмного забезпечення існує чимало платформ, котрі можуть об’єднувати в собі одну або, навіть, декілька з вказаних функцій. Наприклад, це такі відомі платформи, як Jaeger (збір телеметричних даних, бекенд трейсів, візуалізація запитів), Grafana (аналіз та візуалізація трейсів, перегляд логів), Loki (джерело логів), Tempo (бекенд трейсів), cAdvisor (збір та відображення статистичних даних контейнерів кластеру), Fluentd (централізоване логування), Zabbix (моніторинг розподіленої інфраструктури),Prometheus (джерело метрик та генератор Alert-повідомлень)та інші. Всі вони сумісні з платформами контейнеризації або, навіть, інтегровані в них, як, наприклад cAdvisor із Kubernetes.
У статті наведено приклад реалізації однієї з розповсюджених конфігурацій Observability-системи, котра включає стек технологій Grafana + Loki + Prometheus. Нижче будуть розглянуті декотрі особливості використання вказаних технологій.
Логування
Процес логування дозволяє зібрати вихідну інформацію про роботу додатку для подальшого аналізу та візуалізації результатів. Традиційні системи логування, до яких, зокрема, відноситься відомий стек ELK (Elasticsearch, Logstash и Kibana) виконують повний парсінг строк журналів, утворюючи при цьому величезний за обсягом індекс, котрий завжди знаходиться в пам’яті. Незважаючи на велику швидкість пошуку, це вимагає значних витрат ресурсів і тому неефективно.
Loki є альтернативним варіантом традиційним системам логування, котрий виконує індексацію лише метаданих журналів із утворенням невеликого за обсягом індексу. Окрім того, запит розділяється на кілька частин, котрі виконуються паралельно. Це дозволяє отримати високу швидкість обробки даних із невеликими ресурсними витратами. Саме тому вказана технологія стала популярною.
Стек Loki складається із трьох основних елементів (див. Малюнок 2):
-
Сервер для обробки та зберігання логів;
-
Обробник для збирання логів з хостів та передачі їх на сервер;
-
Зовнішній сервіс, на котрий передаються дані для аналізу та виводу у дашборді.
У якості обробника може використовуватися Loki Handler або агент Grafana – Promtail, котрий передає на сервер логи у форматі JSON. У якості зовнішнього сервісу виступає Grafana, що стало можливим із появою інтегрованого переглядальника логів Loki, починаючи з версії 6.0.
Для логування даних зазвичай використовується PHP-бібліотека Monolog, що, зокрема, забезпечує відповідність логера відомому стандарту PSR-3.
Для пошуку логів із інтерфейсу Grafana використовується мова запитів LogQL. Слід мати на увазі, що для можливості подальшої кореляції в кожний лог необхідно додавати ідентифікатор трейсу TraceID.
Розгорнути стек Loki можна, скориставшись інструкцією від розробників.
Технічне рішення FREEhost.UA
-
Готовий VPS із Grafana — розгортання та базове налаштування всього за кылька хвилин.
-
Масштабування під навантаження: просте збільшення ресурсів, перехід на виділені сервери або гібридну схему з локальними агентами.
-
Підтримка команди дата-центру — консультуємо щодо налаштування серверу.
Деталі — в розділі VPS сервер з Grafana.
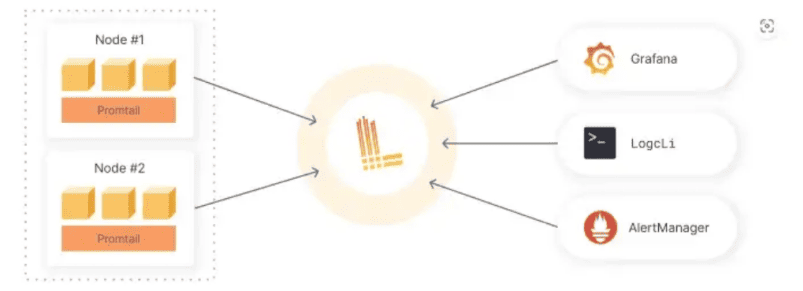
Малюнок 2. Стек елементів Loki.
Збір метрик
Метрики це числові значення параметрів, прив'язані до визначеного проміжку часу. Вони дозволяють визначити працездатність системи та можуть бути різних типів – лічильник, вимірювач або таймер. Для їх збирання код додатку необхідно інструментувати. Для цього зазвичай використовують PHP-бібліотеку prometheus_client або бібліотеку prometheus_exporter, засновану на OpenTelemetry SDK. Це дозволяє збирати, так звані, кастомні метрики, наприклад, такі як кількість помилок чи активних запитів, час відгуку тощо.
Prometheus є однією з найвідоміших систем моніторингу та оповіщень на основі метрик. Він складається з наступних елементів (див. Малюнок 3):
-
Сервер – забезпечує збір та зберігання даних у вигляді часових рядів;
-
Менеджер повідомлень;
-
Бібліотеки клієнтів – слугує для генерування метрик;
-
Push Gateway – дозволяє відправляти метрики із джобів;
-
Експортери – збирають статистичні дані та перетворюють їх у метрики.
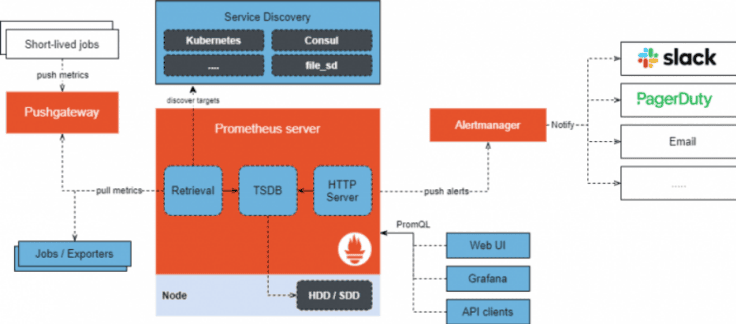
Малюнок 3. Архітектура Prometheus.
Prometheus може інтегруватися зі стеком Loki і виконувати там функції Alert-менеджера (див. Малюнок 2). Це доцільно робити для динамічних систем невеликого розміру. При цьому Loki отримує метрики із логів та передає їх у Prometheus, котрий у випадку виявлення «нестандартних» значень параметрів видає відповідне Alert-повідомлення. Відкривши відповідний дашборд у Grafana, одразу ж можна з’ясувати що не так.
Серед особливостей Prometheus можна вказати на невеликий час зберігання даних, котрий складає чотирнадцять днів. І тому у випадку потужних систем із перспективою подальшого масштабування для зберігання метрик доцільно використовувати Grafana Mimir із необмеженим часом зберігання.
Трейсінг
Трейси дозволяють відслідковувати шлях руху запиту у будь-якій розподіленій системі і є незамінним засобом отримання достовірних результатів та швидкого прийняття рішень стосовно продуктивності коду та виявлення помилок.
Трейси складаються з наборів span-діапазонів, визначених для кожної з операцій на шляху виконання запиту. Зберігаються у бекендах трейсів.
Tempo це розподілений бекенд трейсів, котрий є окремим модулем Grafana. Його архітектура наведена на Малюнку 4.
Експорт span-діапазонів у Grafana Tempo зазвичай здійснюється за протоколом OTLP. Після цього вони потрапляють до розподільника Distributor. Перед тим відбувається інструментація коду додатку за допомогою засобів бібліотеки OpenTelemetry SDK у ручному чи автоматичному режимі (HTTP, Doctrine, Guzzle).
Трейси зберігаються у об’єктній базі даних (Storage) та постачаються за запитом із Grafana. Для отримання наскрізної аналітики у дашбордах Grafana, слід у логах обов’язково вказувати ідентифікатор трейсів TraceID.
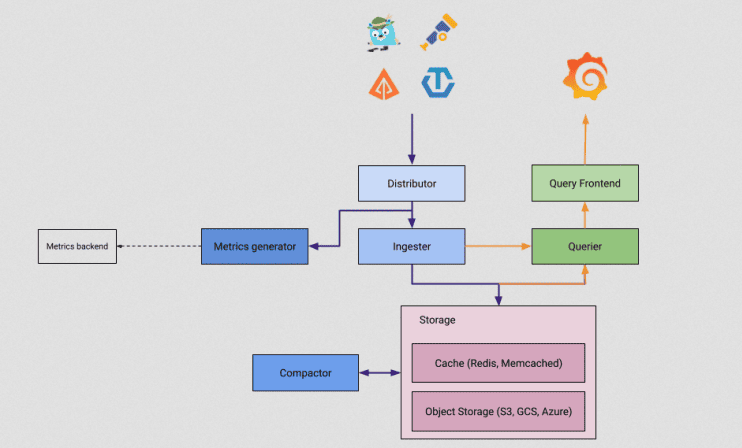
Малюнок 4. Архітектура Tempo.
Профайлінг
Профілювання коду додатку дозволяє визначити місцезнаходження «потенційно небезпечної» або «недосконалої» ділянки коду. Для цього використовуються, так звані, профайлери. Найбільш відомі із open source рішень – Xdebug, XHProf, PHP Spy та Excimer. Серед комерційних інструментів можна виділити Tideways, Blackfire, Datadog, їх ми не розглядаємо.
Профайлер Xdebug найкраще підійде для локального профайлінгу або дебаггінгу. Але у якості основного інструменту його використовувати не можна.
Профайлер XHProf не підтримує OpenTelemetry та з трейсами «не працює». Окрім того, дає високе навантаження при значному рівні трафіку.
Профайлер PHP Spy підтримує OpenTelemetry, але не має стандартних засобів для того, щоб зв’язати профайл з трейсом. І тому у якості основного інструмента для продакшн не підходить.
Профайлер Excimer мінімально навантажує процесор та якнайкраще підходить для продакшена. Встановлюється як окреме розширення PHP. Наведемо декотрі з його особливостей:
-
Генерує Chrome Trace JSON;
-
Має web-UI;
-
Увімкнення/вимкнення через ENV/HTTP-хедер;
-
Вибіркова профілізація slow-endpoints;
-
Інтеграція у CI/CD;
-
Вивантаження у файл формату будь-якого з експортерів;
-
Підтримка профілювання CLI команд;
-
Підтримка FPM.
Скорочена інструкція для php-excimer:
pecl install excimer
; php.ini
extension=excimer.so
excimer.enable=0 ; за замовчуванням вимкнено
// Увімкнення профайлінгу за GET-параметром
if (isset($_GET['profile'])) {
ini_set('excimer.enable', 1);
}
Наведемо приклад організації профілювання додатку за допомогою Excimer:
$profiler = new Excimetry\Excimetry(); // Створюємо профілювальник $profiler->start(); // Початок процесу профілювання // будь-який код додатку // ... // ... $profiler->stop(); // Зупиняємо процес
Технічне рішення FREEhost.UA
Глибока спостережуваність у навантажених проєктах генерує багато даних: логи, трейси, метрики, профілі виконання. Їх потрібно приймати, обробляти й зберігати — це CPU, RAM, диски з високим IOPS та ємністю.
Дата-центр FREEhost.UA пропонує оренду серверів різної конфігурації під ваш стек. Допоможемо підібрати ресурси та за потреби — з первинним налаштуванням. Дізнайтеся більше про про послугу оренди серверу, за посиланням.
Алертінг та SLO/SLI
Механізм алертінгу в Grafana дозволяє моніторити появу затримок (latency) у роботі додатку або будь-яких помилок. Він реалізується шляхом налаштування системи оповіщень на появу будь-яких змін у вхідному потоці метрик або записів журналів. Це автоматизує процес моніторингу та утворює лінію захисту від несподіваних збоїв системи та будь-яких несанкціонованих змін у її роботі. Слід зазначити, що без вказаного механізму метрики взагалі не має сенсу використовувати.
За допомогою Grafana Alerting створюються вирази та запити із використанням кількох джерел даних, котрі можна у подальшому об’єднувати за метриками та журналами в незалежності від джерела їх надходження. Документацію по використанню Grafana Alerting можна почитати тут.
Приклад повідомлення від Grafana Alerting наведений на Малюнку 5.
Малюнок 5. Повідомлення від Grafana Alerting.
На сайті хостінг-провайдера FREEhost.UA можна знайти огляд тарифів на хмарні та відокремлені сервери, а також готові шаблони із Grafana / Loki / Tempo.
Кількісно оцінити роботу будь-якого сервісу можна за допомогою індикатору користувацького досвіду SLI (Service Level Indicator), котрий відслідковує ряд параметрів, пов’язаних із користувацьким досвідом – процент помилок, доступність, час відгуку тощо.
Показник SLO (Service Level Objectives) визначає цільове значення SLI, котре встановлюється для кожного індикатора або їх групи. Тобто, він є внутрішнім показником роботи додатку.
Наведемо основні кроки для активації механізму контролю якості SLO / SLI:
-
Визначити операції або дії, критичні з точки зору користувачів;
-
Для обраних операцій визначити набір метрик, котрі увійдуть до SLI;
-
Визначити поточний розподіл значень метрик;
-
Визначити SLO з урахуванням поведінки обраних метрик та встановити Error Budget;
-
Визначити інструкції на випадок, якщо Error Budget вичерпається;
-
Здійснювати моніторинг встановлених SLO для відповідних індикаторів користувацького досвіду у часовому просторі;
-
Оцінити результати впровадження механізму контролю якості відповідно до Plan-Do-Check-Act.
Реалізація вказаної методики у Grafana здійснюється за допомогою засобів формування запитів PromQL (для метрик) та LogQL (для логів) із відображенням результатів у відповідних дашбордах.
Висновки
У результаті розгляду наведених нами рішень та підходів до вивчення поведінки додатку стає зрозумілим, що для отримання достовірних та повних результатів за допомогою Observability-системи необхідна доступність наступних даних та методів: Логи + метрики + трейси + профайлінг.
Підписуйтесь на наш телеграм-канал https://t.me/freehostua, щоб бути в курсі нових корисних матеріалів.
Дивіться наш канал Youtube на https://www.youtube.com/freehostua.
Ми у чомусь помилилися, чи щось пропустили?
Напишіть про це у коментарях, ми з задоволенням відповімо та обговорюємо Ваші зауваження та пропозиції.
|
Дата: 24.07.2025 Автор: Олександр Ровник
|
|
Авторам статті важлива Ваша думка. Будемо раді його обговорити з Вами:
comments powered by Disqus