


Мы уверенны что среди наших клиентов, есть много профессионалов IT, работающих над интересными проектами. Если у Вас возникает желание рассказать о них, Вы можете разместить статью в нашем блоге. А чтоб было интересней, мы сделали конкурс статей, каждый месяц три победителя будут получать призы.
Статья также доступна на украинском (перейти к просмотру).

Содержание:
- Основные сведения о Observability
- Реализация Observability-системы
- Логирование
- Сбор метрик
- Трейсинг
- Профайлингг
- Аллертинг и SLO/SLI
- Выводы
В классических PHP-проектах достаточно было APM-инструментов: они показывали время ответа, ошибки и узкие места. Но по мере роста микросервисов, облачной инфраструктуры и короткоживущих процессов (функции, воркеры, serverless) этот подход теряет эффективность. Данные рассеяны, зависимости сложны, а время на реакцию – минимальное.
Observability отвечает на эти вызовы: вместо "измерить несколько метрик" мы строим полную картину системы через логи, метрики, трейсы и профайлинг. И этот подход также работает для монолита, как и для сложной распределенной архитектуры. Далее разберемся, как это воплотить в PHP на практике.
Основные сведения о Observability
Термин Observability стал широко известен с 60-х годов прошлого века в связи с публикацией инженером Кальманом научной работы по теории управления. Согласно определенной автором концепции, указанный термин является мерой того, насколько легко можно определить состояние системы по исходным данным. Для области программирования термин имеет одно и то же содержание, но в качестве исходной информации здесь используется набор телеметрических данных, основными из которых являются следующие:
-
Метрики;
-
Журналы;
-
Трейсы.
Observabilityphp эффективно «работает» только при условии наличия достаточного количества телеметрических данных, и чем их больше, тем более «прозрачным» будет поведение приложения. Это напрямую влияет на время реагирования разработчиков на возникающие проблемы в его работе и способствует повышению эффективности разработки/сопровождения.
Телеметрические данные собираются из эндпойнтов приложения и сервисов из разных источников. Это реализуется путем выполнения инструментации приложения, которое может быть нативным или внешним. В первом случае в тело программы имплантируется служебный код для генерирования телеметрических данных. Во втором случае может быть применена одна из технологий, например, eBPF или sidecar. После этого происходит сопоставление данных из разных источников, их анализ и визуализация.
Для облачных сред со сложной архитектурой Observability должна учитывать не только «традиционные» телеметрические данные, которые мы уже рассмотрели, но и многие другие (см. Рисунок 1):
-
Метаданные;
-
Топология и картография сети;
-
Информацию на уровне кода;
-
Поведение пользователей.
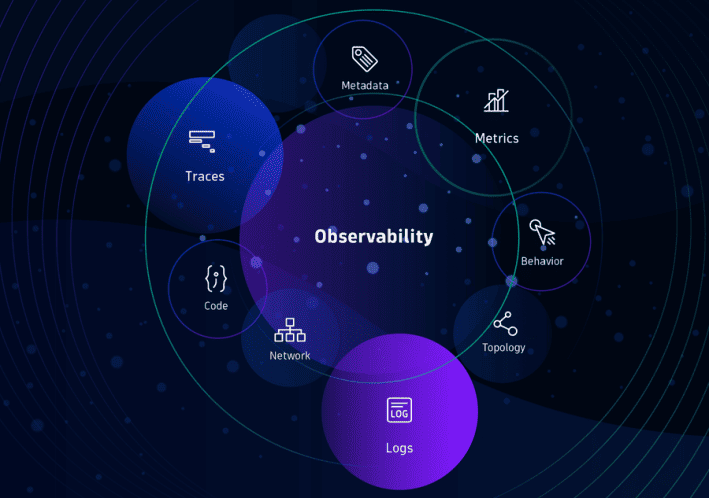
1. Набор телеметрических и других данных для включения в Observability.
Ключевым отличием Observability от традиционного мониторинга есть реализация концепции «unknown unknowns», согласно которой в процессе наблюдения происходит выявление условий, которые в большинстве случаев заранее неизвестны разработчикам. После этого отслеживается их связь с определенными проблемами производительности, что дает более глубокий контекст для выявления первопричины и ускоряет решение проблемы.
В то же время, при традиционном мониторинге, наоборот, заранее определено, что именно нужно искать, то есть здесь работает принципиально отличная концепция. «unknown unknowns», что позволяет только «получить уведомление» о превышении критических значений параметров. Но причину этого найти гораздо труднее.
Можно выделить следующие преимущества нового подхода:
-
возможность выявления и устранения проблем на начальных этапах разработки;
-
Улучшение пользовательского опыта;
-
Автоматизация устранения недостатков и самообновления инфраструктуры приложения при применении ИИ;
-
Автоматическое масштабирование;
-
Безопасный деплой;
-
Минимизация среднего значения времени обновления (MTTR - Mean Time To Resolve).
Реализация Observability-системы
Современные системы наблюдения обычно включают в себя стек известных платформ или технологий, каждая из которых может реализовывать определенную функциональность. Приведем основные из этих функций:
-
средства инструментации кода приложения;
-
Сбор, хранение и доставка телеметрических данных;
-
Распределенный бэкенд трейсов;
-
Генераторы Alert-сообщений для клиентов;
-
Средства поиска;
-
корреляция работы компонентов распределенной системы;
-
Анализ данных и их визуализация.
На рынке программного обеспечения существует немало платформ, которые могут объединять в себе одну или даже несколько из указанных функций. Например, это такие известные платформы, как Jaeger (сбор телеметрических данных, бэкенд трейсов, визуализация запросов), Grafana (анализ и визуализация трейсов, просмотр логов), Loki (источник логов), Tempo (бэкенд трейсов), cAdvisor (сбор и отображение статистических данных контейнеров кластера), Fluentd (централизованное логирование), Zabbix (мониторинг распределенной инфраструктуры),Prometheus (источник метрик и генератор Alert-сообщений)и другие. Все они совместимы с платформами Kubernetes.
В статье приведен пример реализации одной из распространенных конфигураций Observability-системы, включающей стек технологий Grafana + Loki + Prometheus. Ниже будут рассмотрены некоторые особенности использования указанных технологий.
Логирование
Процесс логирования позволяет собрать исходную информацию о работе приложения для дальнейшего анализа и визуализации результатов. Традиционные системы логирования, к которым, в частности, относится известный стек ELK (Elasticsearch, Logstash и Kibana) выполняют полный парсинг срок журналов, образуя при этом огромный по объему индекс, всегда находящийся в памяти. Несмотря на огромную скорость поиска, это просит значимых издержек ресурсов и потому неэффективно.
Loki является альтернативным вариантом традиционным системам логирования, выполняющим индексацию только метаданных журналов с образованием небольшого по объему индекса. Кроме того, запрос разделяется на несколько частей, выполняемых параллельно. Это позволяет получить высокую скорость обработки данных с небольшими ресурсными издержками. Именно поэтому эта технология стала популярной.
Loki состоит из трех основных элементов (см. Рисунок 2):
-
Сервер для обработки и хранения логов;
-
Обработчик для сбора логов с хостов и передачи их на сервер;
-
Наружный сервис, на который передаются данные для анализа и вывода в дашборде.
В качестве обработчика может использоваться Loki Handler или агент Grafana -Prometheus передающий на сервер логи в формате JSON. В качестве внешнего сервиса выступает Grafana что стало возможным с появлением интегрированного просмотрщика логов Loki, начиная с версии 6.0.
Для логирования данных обычно используется PHP-библиотека Monolog, что, в частности, обеспечивает соответствие логера известному стандарту PSR-3.
Для поиска логов по интерфейсу Grafana используется язык запросов LogQL. Следует иметь в виду, что для возможности дальнейшей корреляции каждый лог необходимо добавлять идентификатор трейса. TraceID.
Развернуть стек Loki можно, воспользовавшись инструкцией от разработчиков.
Техническое решение FREEhost.UA
-
Готовый VPS из Grafana — развертывание и базовая настройка всего за несколько минут.
-
Масштабирование под погрузку: простое увеличение ресурсов, переход на выделенные серверы или гибридную схему с локальными агентами
-
Поддержка команды дата-центра — консультируем по настройке сервера.
Подробности — в разделе VPS-сервер от Grafana.
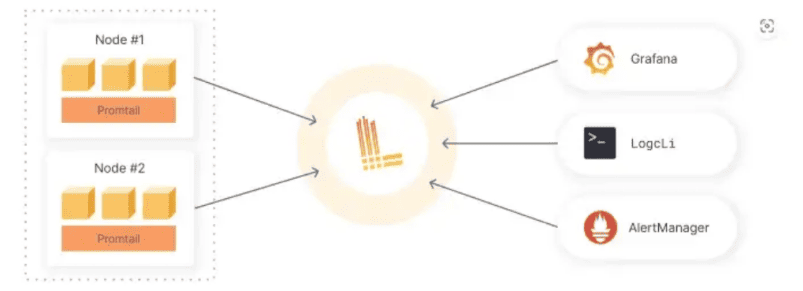
Рисунок 2. Стек элементов Loki.
Сбор метрик
Метрики – это числовые значения параметров, привязанные к определенному промежутку времени. Они позволяют определить работоспособность системы и могут быть разных типов – счетчик, измеритель или таймер. Для их сбора код приложения необходимо инструментировать. Для этого обычно используют PHP-библиотекуprometheus_client или библиотеку prometheus_exporter, основанную на SDK OpenTelemetry. Это позволяет собирать так называемые кастомные метрики, например, такие как количество ошибок или активных запросов, время отклика и т.д.
Prometheus является одной из известнейших систем мониторинга и оповещений на основе метрик. Он состоит из следующих частей (см. Рисунок 3):
-
Сервер – обеспечивает сбор и хранение данных посредством временных рядов;
-
Менеджер сообщений;
-
Библиотеки клиентов – служит для генерирования метрик;
-
Push Gateway – позволяет отправлять метрики из джобов;
-
Экспортеры – собирают статистические данные и превращают их в метрики.
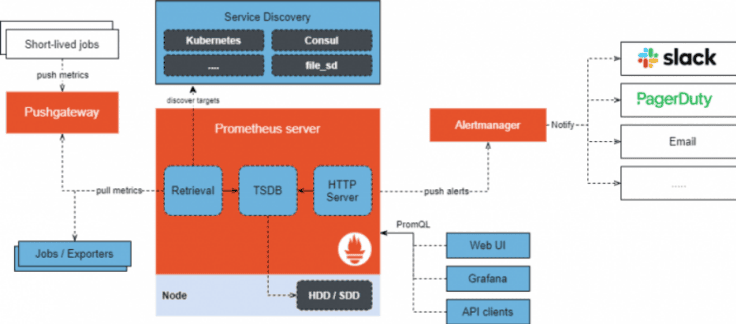
Рисунок 3. Архитектура Prometheus.
Prometheus может интегрироваться со стеком Loki и выполнять там функции Alert-менеджера (см. Рисунок 2). Это целесообразно делать для динамических систем маленького размера. При этом Loki получает метрики из логов и передает их в Prometheus, который в случае обнаружения «нестандартных» значений параметров выдает соответствующее Alert-сообщения. Открыв соответствующий дашборд в Grafana, сразу же можно выяснить, что не так.
Среди особенностей Prometheus можно указать на небольшое время хранения данных, составляющее четырнадцать дней. И поэтому в случае мощных систем с перспективой дальнейшего масштабирования для хранения метрик целесообразно использовать Grafana Mimir с неограниченным временем хранения.
Трейсинг
Трейсы позволяют отслеживать путь запроса в любой распределенной системе и являются незаменимым средством получения достоверных результатов и быстрого принятия решений относительно производительности кода и выявления ошибок.
Трейсы состоят из наборов span-диапазонов, определенных для каждой из операций для выполнения запроса. Сохраняются в бэкендах трейсов.
Время это распределенный бэкенд трейсов, являющийся отдельным модулем. Grafana. Его архитектура приведена на Рисунку 4.
Экспорт span-диапазонов в Grafana Tempo обычно осуществляется по протоколу OTLP. После этого они попадают в распределитель Distributor. Перед этим происходит инструментация кода приложения с помощью средств библиотеки SDK OpenTelemetry в ручном или автоматическом режиме (HTTP, Doctrine, Guzzle).
Трейсы хранятся в объектной базе данных (Storage) и поставляются по запросу из Grafana. Для получения сквозной аналитики в дашбордах Grafana Mimir, следует в логах обязательно указывать идентификатор трейсов TraceID.
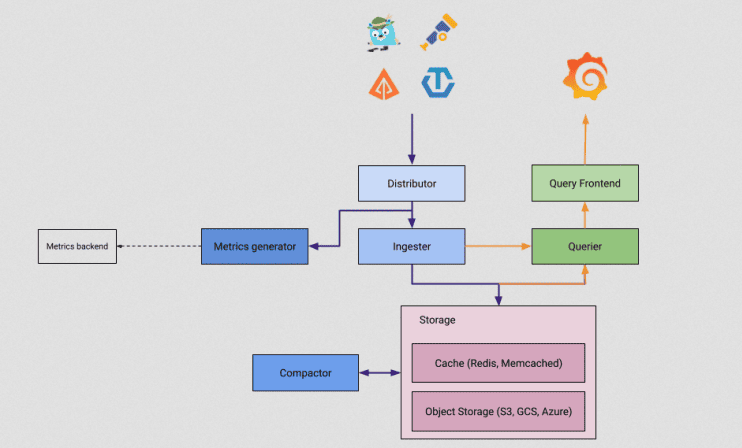
Рисунок 4. Архитектура Tempo.
Профайлинг
Профилирование кода приложения позволяет определить местонахождение «потенциально опасного» или «несовершенного» участка кода. Для этого используются так называемые профайлеры. Наиболее известные из с открытым исходным кодом решений – Xdebug, XHProf, PHP Spy и Excimer. Среди коммерческих инструментов можно выделить Tideways, Blackfire, Datadog, их мы не рассматриваем.
Профайлер Xdebug лучше всего подойдет для локального профайлинга или дебаггинга. Но в качестве основного инструмента использовать его нельзя.
Профили XHProf не поддерживает OpenTelemetry и с трейсами "не работает". Кроме того, дает высокую нагрузку при значительном уровне трафика.
Профили PHP-Spy поддерживает OpenTelemetry, но нет стандартных средств для того, чтобы связать профайл с трейсом. И потому в качестве основного инструмента для продакшна не подходит.
Профили Excimer минимально нагружает процессор и лучше подходит для продакшена. Устанавливается как отдельное расширение PHP. Приведем некоторые из его особенностей:
-
Генерирует Chrome Trace JSON;
-
Имеет web-UI;
-
Включение/выключение через ENV/HTTP-хедер;
-
Выборочная профилизация медленные конечные точки;
-
Интеграция в CI/CD;
-
Выгрузка в файл формата любого из экспортеров;
-
Поддержка профилирования команд CLI;
-
Поддержка FPM.
Сокращенная инструкция для php-excimer:
pecl install excimer
; php.ini
extension=excimer.so
excimer.enable=0; по умолчанию отключено
// Включение профайлинга по GET-параметру
if (isset($_GET['profile'])) {
ini_set('excimer.enable', 1);
}
Приведем пример организации профилирования приложения с помощью Excimer:
$profiler = New Excimetry\Excimetry(); // Создаем профилировщик $profiler->start(); // Начало процесса профилирования // любой код приложения // ... // ... $profiler->stop(); // Останавливаем процесс
Техническое решение FREEhost.UA
Глубокая наблюдаемость в нагруженных проектах генерирует много данных: логи, трейсы, метрики, профили исполнения. Их нужно принимать, обрабатывать и хранить – это CPU, RAM, диски с высоким IOPS и емкостью.
Дата-центр FREEhost.UA предлагает аренду серверов разной конфигурации под ваш стек. Поможем подобрать ресурсы и при необходимости с первичной настройкой. Узнайте больше об услуге аренды сервера, по ссылке.
Аллертинг и SLO/SLI
Механизм аллертинга в Grafana позволяет мониторить появление задержек (задержка) в работе приложения или любых ошибок. Он реализуется путем настройки системы оповещений на появление каких-либо изменений во входящем потоке метрик или записей журналов. Это автоматизирует процесс мониторинга и образует линию защиты от неожиданных сбоев системы и любых несанкционированных изменений ее работы. Следует отметить, что без указанного механизма метрики вообще нет смысла использовать.
При помощи Grafana Alerting создаются выражения и запросы с использованием нескольких источников данных, которые можно в дальнейшем объединять по метрикам и журналам независимо от источника их поступления. Документацию по использованию Grafana Alerting можно почитать здесь.
Пример сообщения от Grafana Alerting приведен на Рисунке 5.
Рисунок 5. Сообщение от Grafana Alerting.
На сайте хостинг-провайдера FREEhost.UA можно найти обзор тарифов на облачные и обособленные серверы, а также готовые шаблоны с Grafana / Loki / Tempo.
Количественно оценить работу любого сервиса можно с помощью индикатора пользовательского опыта SLI (Service Level Indicator), отслеживающий ряд параметров, связанных с пользовательским опытом – процент ошибок, доступность, время отклика и т.д.
Показатель SLO (Service Level Objectives) определяет целевое значение SLI, устанавливаемое для каждого индикатора или их группы. То есть он является внутренним показателем работы приложения.
Приведем основные шаги по активации механизма контроля качества SLO / SLI:
-
Определить операции или действия, критичные с точки зрения пользователей;
-
Для выбранных операций определить набор метрик, которые войдут в SLI;
-
Определить текущее распределение значений метрик;
-
Определить SLO с учетом поведения выбранных метрик и установить Error Budget;
-
Определить инструкции на случай, если Error Budget иссякнет;
-
Осуществлять мониторинг установленных SLO для соответствующих индикаторов пользовательского опыта во временном пространстве;
-
Оценить результаты внедрения механизма контроля качества в соответствии с Plan-Do-Check-Act.
Реализация указанной методики в Grafana осуществляется посредством средств формирования запросов PromQL (для метрик) и LogQL (для логов) с отображением результатов в соответствующих дашбордах.
Выводы
В результате рассмотрения приведенных нами решений и подходов к изучению поведения приложения становится ясно, что для получения достоверных и полных результатов с помощью Observability-системы необходима доступность следующих данных и методов: Логи + метрики + трейсы + профайлинг.
Подписывайтесь на наш телеграмм-канал https://t.me/freehostua, чтобы быть в курсе новых полезных материалов
Смотрите наш канал Youtube на https://www.youtube.com/freehostua.
Мы в чем ошиблись, или что-то пропустили?
Напишите об этом в комментариях, мы с удовольствием ответим и обсуждаем Ваши замечания и предложения.
|
Дата: 24.07.2025 Автор: Александр Ровник
|
|
Авторам статьи важно Ваше мнение. Будем рады его обсудить с Вами:
comments powered by Disqus