





Що таке embedding (ембедінги)?
Стаття також доступна російською (перейти до перегляду).
Ембедінг (embedding) – це технологія перетворення даних (тексту, зображень, відео, аудіо) у вектори, що зберігаються у векторній базі даних. Таке векторне представлення дає можливість машині шукати подібні частинки інформації, навчатись бачити подібність понять та адекватно передбачувати наступний елемент.
У цій статті ми розберемося, що означає поняття embedding, принцип роботи технології, і чому саме ембедінги є фундаментом для ефективної взаємодії мовних моделей з людською мовою та даними загалом.
Що таке embedding простими словами
Ембедінг – це спосіб перетворити текст, зображення або інші дані на набір чисел так, щоб ШІ «розумів» їхній зміст. Простіше кажучи, він показує подібність даних: наприклад, слова з високою семантичною подібністю мають схожі числа, різні – далекі.
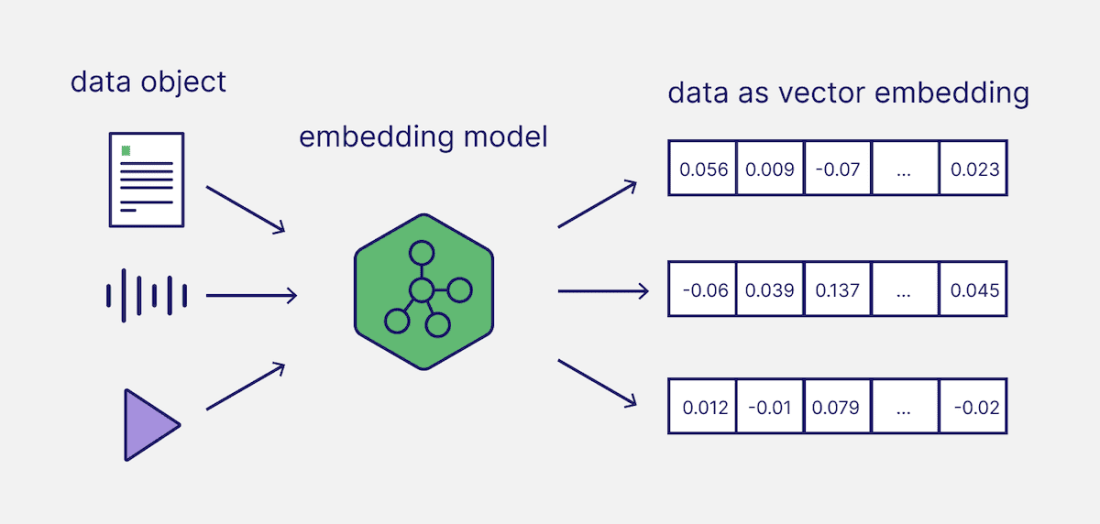
Для того, аби було легше зрозуміти суть поняття, використаємо кілька аналогій. Embedding можна порівняти з:
-
Картою. Завдяки координатам на мапі ми можемо сказати, які міста розташовані близько одне до одного, навіть не знаючи нічого про їхні назви. Так само в ембедінгах кожен елемент отримує свої координати у багатовимірному просторі. Якщо значення схожі, ці «точки» будуть поруч.
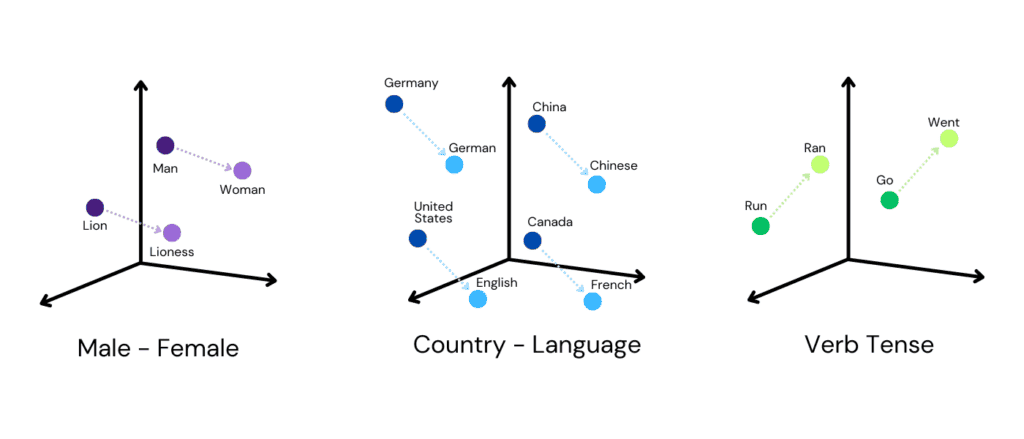
- Числовим представленням тексту. Наприклад, слово «кіт» для моделі стає не текстом, а числовим вектором, у якому зашифровано, що це тварина і поняття, близьке за змістом до слова «собака», але далеке від «автомобіль». AI-модель не знає, що таке кіт у реальному світі, але вона бачить, як це слово використовується і з чим воно пов’язане.
Ембендінг не є простим текстом чи числовими даними. Це векторне представлення змісту. На відміну від тексту, який людина читає буквально, векторні дані зберігають сенс і контекст у вигляді чисел. А на відміну від звичайних чисел (наприклад, ціни чи кількості), кожне число в embedding не має окремого значення, важливе лише їх поєднання та відстань між ними.
Як працюють ембедінги
Загалом принцип роботи полягає в тому, що модель проводить аналіз змісту (тексту, слів, зображення, відео) і перетворює його на набір чисел (вектор). Вектор тут, як і в математиці, означає впорядкований набір чисел. Його можна уявити як точку в багатовимірному просторі. І саме відстань між векторами стає мірою схожості: чим ближче вектори, тим більш схожий їхній зміст.
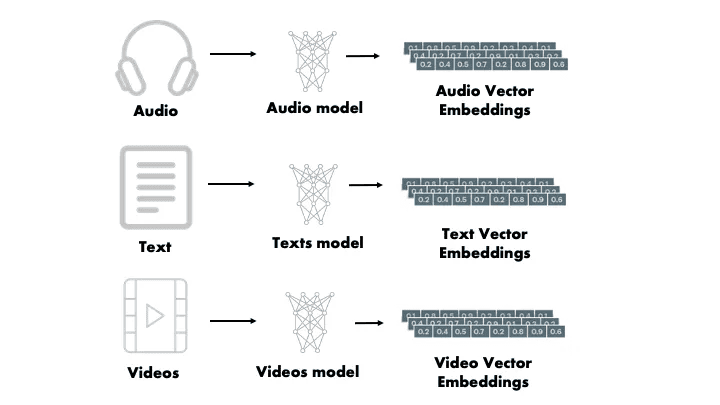
- Для зображень. Векторизовані дані зображень описують їх візуальний зміст: форми, об’єкти, стилі, сцени. Це дає змогу знаходити схожі зображення, розпізнавати об’єкти або поєднувати зображення з текстом (наприклад, пошук картинки за описом).
- Для аудіо/відео. Аудіо- та відеоембедінги кодують звук або відеоряд у числове представлення, яке зберігає ключові характеристики: мову, інтонацію, події, рух або сцену. Їх використовують для розпізнавання мовлення, пошуку по відео, рекомендацій контенту та аналізу мультимедіа.
Саме векторне представлення дозволяє ШІ-моделям навчатися на основі людських даних і мати змогу генерувати максимально схожий контент за запитом. Задані запити до моделі теж перетворюються в числові значення і модель «розуміє» що саме хоче згенерувати користувач.
Де використовуються ембедінги
Технологія допомагає не тільки у навчанні штучного інтелекту, але і у його практичних застосуваннях. Без ембедінга не будуть існувати:
-
-
Пошукові системи нового покоління (semantic search) – знаходження релевантної інформації на основі смислової близькості, а не точних збігів слів.
-

- Рекомендаційні системи– пропозиції контенту, товарів чи послуг, спираючись на схожість інтересів або характеристик.
- Класифікація тексту– автоматичне розподілення текстів за категоріями, темами або тональністю.
- Чат-боти та RAG-системи – відповіді на запити користувачів на основі інформації з баз знань або документів.
- SEO/робота з контентом – аналіз, структурування та оптимізація текстів для швидкого пошуку та обробки.
- Завдяки цьому способу аналізу AI може швидко знаходити, порівнювати та обробляти інформацію за змістом, а не лише за словами.
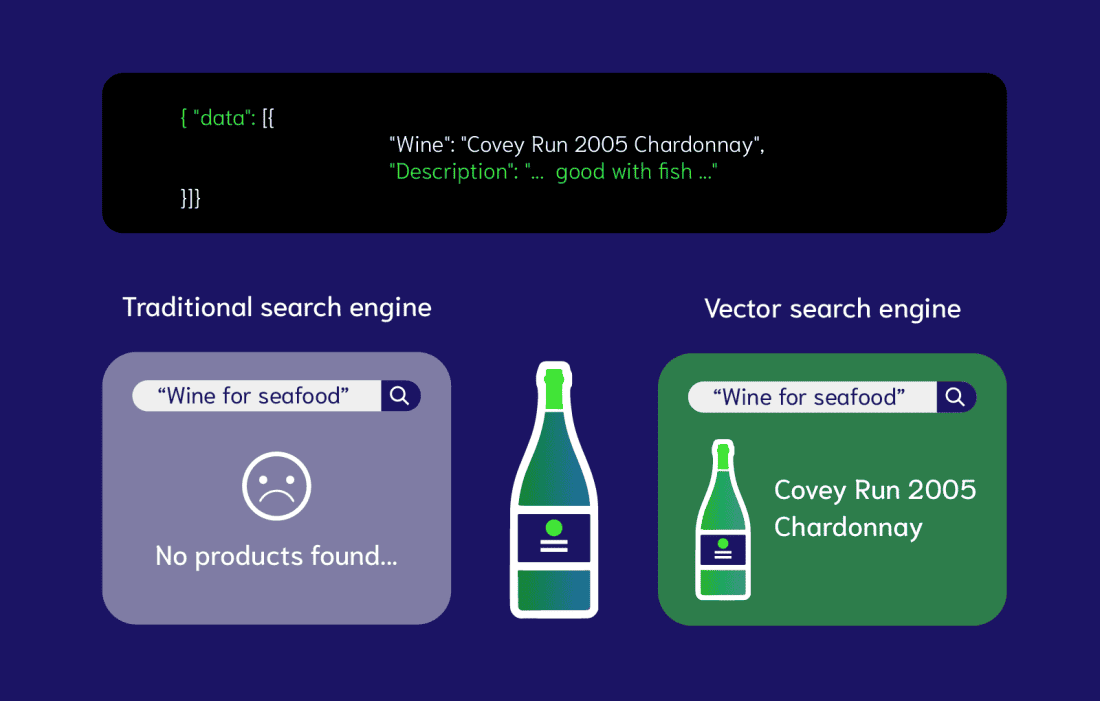
Чим embeddings відрізняються від keyword-пошуку
Вектори працюють зі значенням слів і їхнім контекстом, а не з буквальним написанням. Завдяки цьому вони показують, наскільки поняття або ідеї схожі за змістом, навіть якщо слова різні. І це головна перевага ШІ-пошуку над пошуком за ключовими словами.
| Показник | Embeddings | Keyword |
|---|---|---|
| Принцип роботи | Пошук за змістом і семантикою | Пошук точних збігів слів або фраз |
| Гнучкість | Може знаходити релевантні результати без точних формулювань | Повертає результати лише з точними ключовими словами |
| Розуміння контексту | Так, враховує значення, контекст і семантику | Ні, лише буквальні збіги |
| Синоніми та варіації | Розпізнає синоніми та близькі за змістом формулювання | Не розпізнає синоніми |
Навіть якщо ви не розробник, розуміння принципів роботи embeddings допомагає краще організовувати пошук, рекомендації та аналіз контенту для сайту. Завдяки підтримці з боку хостинг-провайдера FREEhost.UA ви можете інтегрувати інтелектуальні інструменти для обробки інформації, роблячи роботу з даними на сайті простішою та ефективнішою. Для роботи з невеликими об’ємами даних достатньо буде VPS серверу. Якщо Ви плануєте побудувати RAG систему підприємства, або використовувати ШІ для вирішення складних завдань, бажано використовувати сервер з потужною відеокартою.