





Что такое векторная база данных?
Статья также доступна на украинском (перейти к просмотру).
LLM (Большая языковая модель) не может работать без входной информации. Для того чтобы «кормить» ему текст, изображения и аудио, нужно их превратить в векторные вложения, то есть числовые векторные значения, которые искусственный интеллект способен проработать. Они хранятся в векторной базе данных. Но что такое векторная база данных по существу?
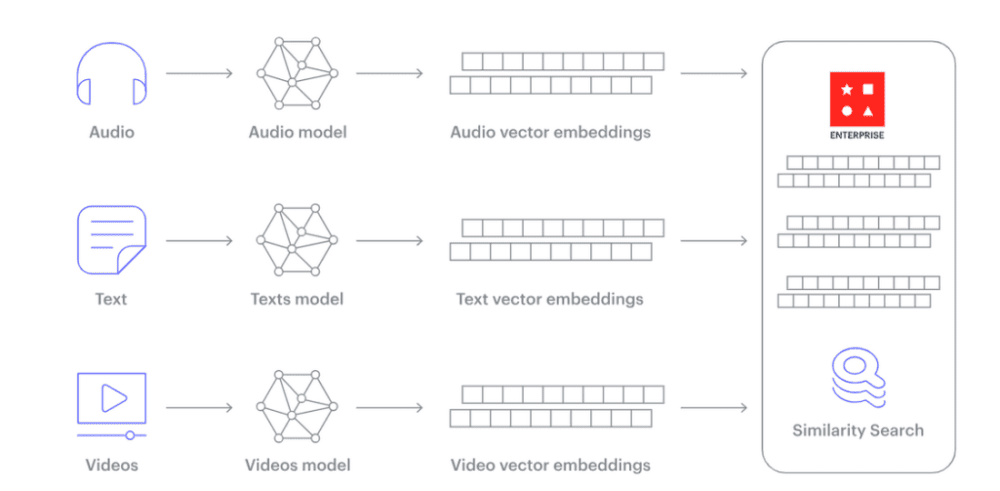
Расшифровка понятия
Векторная база данных – это специализированная система для хранения, индексации векторов и поиск векторных вложений (эмбеддингов).Встраивание – это многомерное представление данных, где текст, аудио или изображение преобразовано в числа и векторы.
В векторной базе данных близкие по содержанию элементы имеют ближайшее месторасположение. такое хранилище данных будет оптимизировано за подобием векторов. Например, понятия «кот» и «котенка» будут рядом, тогда как в традиционном хранилище, ищущем по точному совпадению, они не будут родственны.
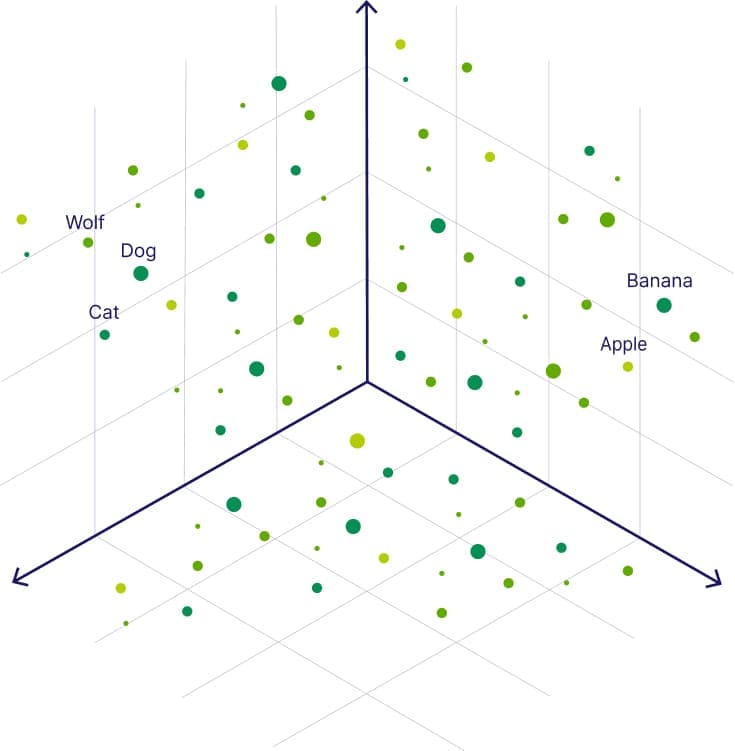
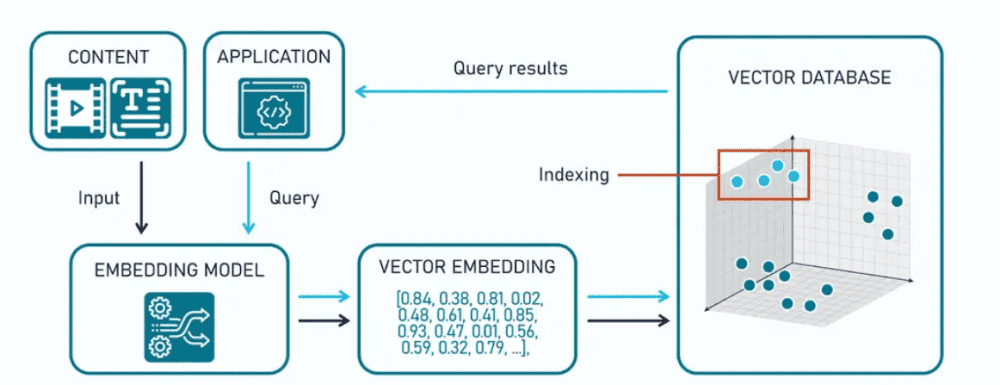
Как работает векторная база данных
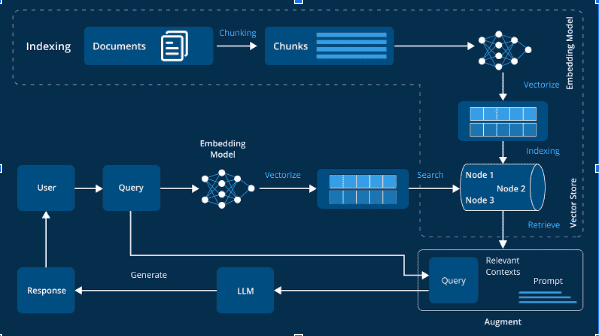
Ее можно представить как семантический поисковик, оперирующий не словами, а смыслами, представленными в виде векторов. Это работает так:
-
Векторизация. Данные (тест, изображения, аудио и т.п.) пропускаются через модель, которая создает их числовые представления. вложения.
-
Хранение. Эти числовые значения и векторы вместе с метаданными (ID, текстовый фрагмент, ссылки и т.п.) записываются в хранилище.
-
Индексация. Для быстрого поиска по содержанию база создает индексы (например, HNSW, IVF), позволяющие мгновенно находить ближайшие векторы среди миллионов записей.
-
Поиск по сходству. Запрос, отправленный пользователем, также векторизируется. Затем он сравнивается с другими элементами в поиске наибольшей близости (cosine similarity, euclidean distance и т.п.).
-
Выдача результатов. Система возвращает ближайшие объекты, которые модель или приложение могут использовать согласно своему алгоритму.
База выступает одним из инструментов машинного обучения – благодаря векторному представлению данных модели могут быстро находить. да сравнивать объекты по содержанию, усиливая свои ответы контекстом и работать с большими массивами информации в реальном времени.
Где применяется
Именно векторное представление данных позволяет реализовать системы рекомендаций, семантический поиск, Системы RAG для AI-чат-бота и другие полезные инструменты. В качестве векторного массива используется в каждом из этих случаев:
-
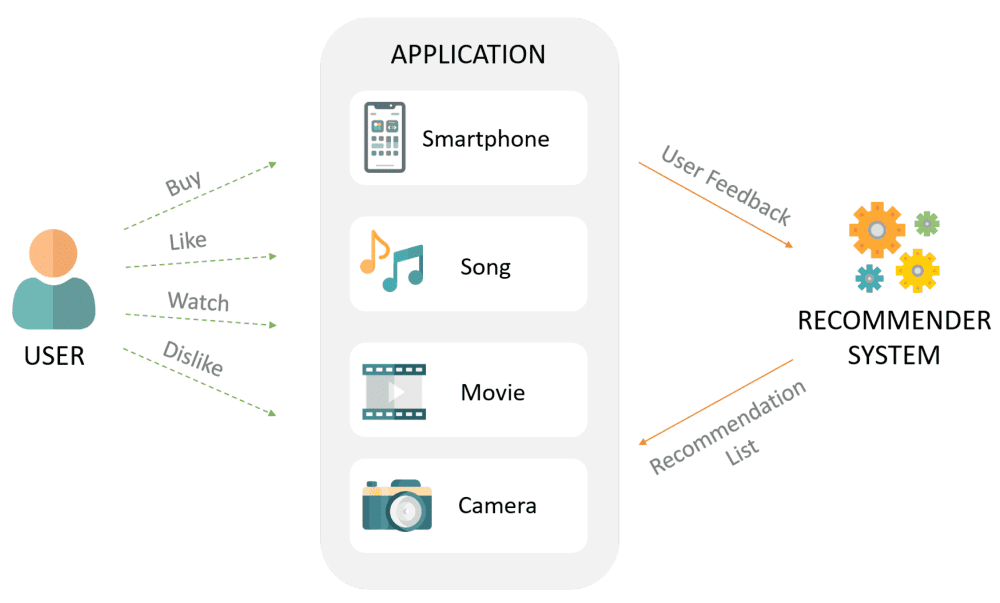
В системе рекомендаций вложения описывают интересы пользователя или характеристики товаров/контента в виде числовых пространств. Система сравнивает векторы между собой и определяет, какие товары или информационные материалы более близки по содержанию. Чем они более схожи, тем более релевантной будет рекомендация.
-
В случае семантического поиска запрос становится вектором, а поисковик подбирает результаты не по ключевым словам, а по смыслу. Это позволяет находить нужную информацию в базе знаний даже тогда, когда формулировка не совпадает с текстом источника.

-
При применении Системы RAG в AI-чат-ботевекторное представление данных обеспечивает поиск требуемой информации и генерацию точного ответа на ее основе. Так ответ становится более точным и обоснованным, с минимальным количеством «галлюцинаций».
В общем-то, она нужна повсюду, где нужно работать с содержанием и контекстом, а не просто с отдельными словами.
Популярные решения
Наиболее распространенными в использовании системами управления векторными данными являются FAISS, Qdrant, Weaviate та Milvus.
FAISS (Facebook AI Similarity Search)
Это библиотека Meta с открытым кодом для поиска подобия и кластеризации векторов. В нем есть алгоритмы, способные искать векторы в миллионных и миллиардных наборах. Она особенно популярна в исследовательских проектах благодаря своей производительности и гибкости, однако, она функционирует как библиотека, а не как полноценная база данных с поддержкой транзакций.
Qdrant
Это векторное хранилище информации с открытым кодом, написанное на Rust. У него есть удобный REST API, фильтрация по метаданным и горизонтальное масштабирование. Она хорошо подходит для production-сред, где требуется не только скорость поиска, но и возможность хранения дополнительных атрибутов вместе с векторами.
Weaviate
Это облачно ориентированная векторная база данных со встроенной поддержкой GraphQL и RESTful API. Она интегрируется с разными моделями машинного обучения и поддерживает семантический поиск, классификацию и рекомендательные системы В ней можно автоматически векторизировать данные и есть инструменты для работы с неструктурированным информацией.
Milvus
Это распределенная векторная база данных, разработанная специально для AI инфраструктуры (приложений, чат-ботов, API для поиска и т.п.). Она поддерживает разные типы индексов, обеспечивает горизонтальное масштабирование и интеграцию с экосистемой больших данных.
Как реализуется
Что такое векторная база данныхна практике? Чаще всего это программное обеспечение, которое можно развернуть локально на собственном компьютере. Докер-контейнере или на специализированном GPU-сервер.
Локальное развертывание подходит для экспериментов, разработки и тестирования небольших проектов. Установив базу на своё устройство, следует понимать, что без мощной вычисления GPU будут занимать больше времени.
Установка Docker организует изолированную среду для базы. Это удобный вариант для DevOps-процессов и развертывания в разных инфраструктурах. Однако ограничение остается прежним: без доступа к GPU производительность будет низкой, особенно при работе с большими объемами данных.
GPU-серверы, которые предлагает Freehost.UA. – это оптимальное решение для production-сред. Графические процессоры специально разработаны для параллельных вычислений, что делает их идеальными для векторных операций.
Разница в производительности между CPU и GPU значительна – индексация миллионов векторов, которая на обычном процессоре займет дни, на GPU может завершиться в час. Поэтому для любых серьезных применений векторных баз данных доступ к качественной GPU является необходимым компонентом.
Запускаете векторные базы и AI-сервисы? Арендуйте GPU-сервер на AMD Ryzen 7 7700 + Nvidia RTX 5060 Ti 16 GB GDDR7 и получите производительность, достаточную для эмбеддингов, RAG и интеллектуального поиска.