





Что такое LLM (Large Language Model)?
Статья также доступна на украинском (перейти к просмотру).
Искусственный интеллект изменил подходы к использованию компьютера достаточно кардинально. Раньше, когда пользователям потребовался ответ на какой-либо вопрос, необходимо было формировать точные и четкие запросы в поисковик. Теперь же вопрос любой сложности будет объяснен почти так же, как бы это сделал реальный человек.
За этим прорывом стоит Large Language Model, что переводится как Большая Языковая Модель. Но точно ли мы понимаем, что такое LLM и как она работает? Чтобы разобраться в этом, посмотрим на ее сущность, принципы работы и возможности.
Определение понятия
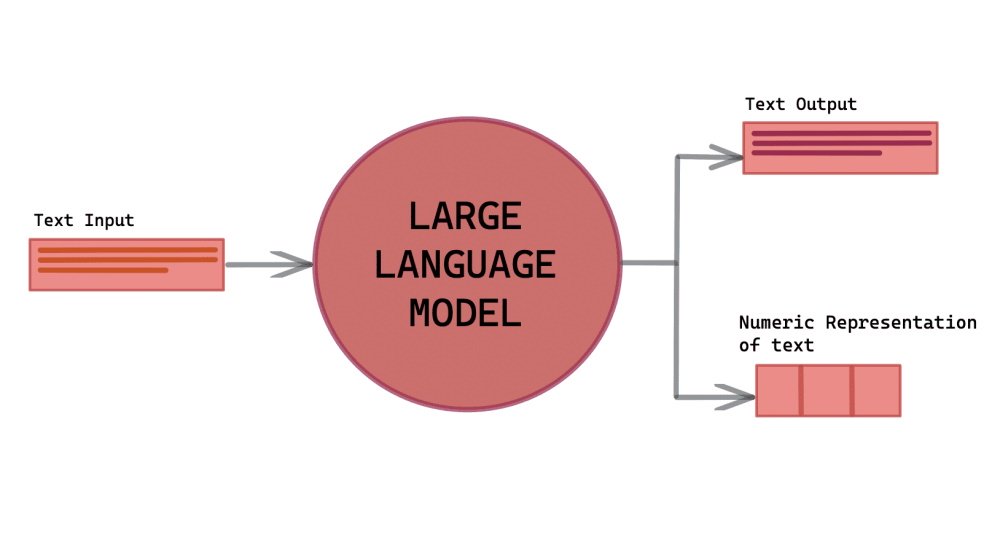
Прежде всего, нам нужно понять, что такое LLM в целом. Это тип AI, который специализируется на обработке естественного языка (NLP) и генерации текстов, которые максимально похожи на человечиские. Среди самых популярных производителей моделей–OpenAI, Google и Anthropic. Их большие языковые модели прошли обучение на текстах, анализируя книги, статьи, вебсайты, коды и другие виды текстовых данных, которые создали люди.
На основе статистических закономерностей языка они могут генерировать новые тексты, отвечать на вопросы, переводить, обобщать и вести диалог. Однако большие языковые модели не имеют сознания и не воспринимают текст так же, как люди. Все, что они делают, – это воспроизводят лингвистические структуры с высокой точностью, имитируя форму и стиль человеческой речи. Их языковое понимание строится на вычислении наиболее вероятного продолжения.
Разница между Large Language Model и генеративным ИИ
Хотя эти 2 понятия часто отождествляют, это не совсем одно и то же. Генеративный ИИ – более широкое понятие, охватывающее технологии создания:
-
текст;
-
изображений;
-
музыки;
-
видео;
-
3D-объекты.
К примеру, Midjourney генерирует изображения, а Sora создает видео – это тоже генеративный AI, но не языковые модели. Лингвистические модели являются подтипом генеративного искусственного интеллекта, специализирующегося именно на работе с языком. Но на практике они часто работают в паре – например, ChatGPT может помочь сформировать промт (точную инструкцию, запрос) для Sora.
Как работает
В основе LLM лежит архитектура трансформера, разработанная в 2017 году. Она использует алгоритмы глубокого обучения, чтобы обучить нейросеть эффективно обрабатывать последовательности слов, сохраняя контекст даже в больших текстах.
В целом, этапы тренировки модели в обработке естественного языка (NLP) такие:
-
"Чтение" текстов. Машинное обучение начинается с разбора большого массива данных. Модель анализирует, как люди строят предложения, какие слова часто встречаются вместе и выводит языковые закономерности, формируя шаблоны.
-
Дробление. Любой обрабатываемый текст разбивается на небольшие кусочки – токены (это могут быть слова, части слова или даже отдельные символы). Последующая работа происходит не с предложениями, а именно с этими токенами, превращающимися в числовой формат.
-
Анализ контекста. Каждый токен рассматривается в контексте всего предложения или запроса. Модель «обращает внимание» на другие слова вокруг, чтобы понять, какое следующее слово наиболее логично.
-
Генерация шаг за шагом. Ответ строится по одному слову, где алгоритм каждый раз выбирает вероятное продолжение согласно контексту.
-
Дополнительная учеба на примерах с участием людей. Специалисты показывают нейросети хорошие и плохие примеры ответов. Так она учится отвечать понятнее, корректнее и безопаснее.
В результате этой работы мы получаем мощное средство, прогнозирующее текст. Машинное обучение позволяет модели знать язык изнутри и гибко совмещать слова в зависимости от контекста. При этом генерация происходит стремительно, а общение смотрится естественно.
Где применяется
Сфер применения Large Language Model множество. Она становится вспомогательной там, где необходимо быстро обрабатывать информацию, создавать контент, автоматизировать рутинные задачи или взаимодействовать с пользователями в естественной форме. Благодаря гибкости параметров модели, такие системы легко адаптируются под конкретные цели бизнеса или индивидуальные потребности.
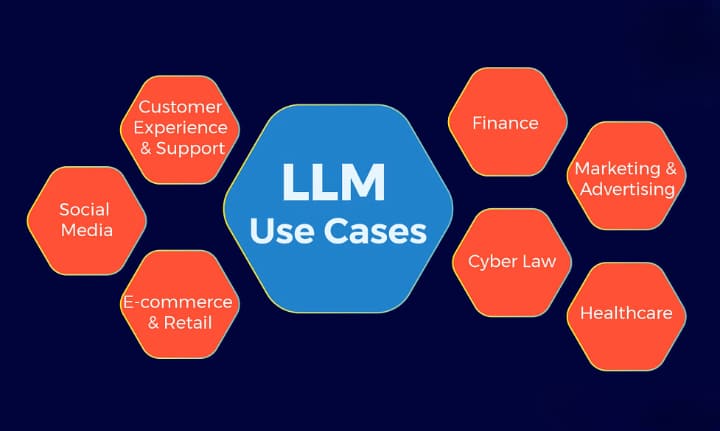
Способы применения технологии ограничиваются только фантазией пользователей. Основные области использования языковых генеративных моделей включают:
-
Образование и науку. Модели объясняют темы, производят контроль знаний, помогают в организации занятий и так далее. В науке они выполняют вычисления, анализируют данные и находят новые подходы к решению проблем.
-
Бизнес. Здесь работа ИИ может заключаться в создании маркетинговых текстов, обслуживании клиентов через чат-боты или анализе рынка и внутренней документации.
-
IT-сферу. AI выступает в роли ассистента для программистов, дополняя код, объясняя ошибки и генерируя функции на основе кратких описаний
-
Креативная индустрия. Здесь они открывают новые возможности для творчества и экспериментов, помогая создавать идеи и улучшать уже созданный контент.
Хорошо ИИ помогает и с продвижением в Интернете. Среди примеров использования LLM в SEO-секторе есть генерация трафика. В статье FREEhost.UA собрал полный гайд для оптимизации сайта, чтобы он появлялся в ссылках выдачи GPT и Google AI-снипетов.
Преимущества и недостатки использования
Как и любая технология, генеративные лингвистические модели значительно упрощают работу людям, но также несут за собой новые вызовы. Таблица содержит основные положения, иллюстрирующие преимущества и риски.
|
+ |
- |
|
Скорость обработки больших объемов информации |
Генерация вымышленных фактов, если нет точной информации |
|
Возможность персонализации ответов |
Воспроизведение предупреждений, содержащихся в изученных данных |
|
Доступность для различных отраслей без глубоких технических знаний |
Открытые вопросы безопасности и конфиденциальности |
|
Стимулирование инноваций и автоматизация рутинных задач |
Использование значительных вычислительных ресурсов и энергии |
Такой инструмент, как LLM – ключевая технология будущего. Решение о её использовании зависит от целесообразности в каждом конкретном случае. Но не стоит упускать новые возможности, которые она дает для развития бизнеса и творчества.
Ускорьте свои AI-модели с GPU-сервером FREEhost.UA
Планируете эксперименты с большими речевыми моделями или собственным RAG-сервисом? Выберите сервер с видеокартой AMD Radeon RX 7600 - мощное решение для обучения, инференса и работы с нейронными сетями.
Надежная инфраструктура, круглосуточная поддержка и украинский дата-центр – все для ваших AI-проектов.