


Мы уверенны что среди наших клиентов, есть много профессионалов IT, работающих над интересными проектами. Если у Вас возникает желание рассказать о них, Вы можете разместить статью в нашем блоге. А чтоб было интересней, мы сделали конкурс статей, каждый месяц три победителя будут получать призы.
Статья также доступна на украинском (перейти к просмотру).

Содержание:
Для разработки, доставки и запуска многокомпонентных распределенных приложений широко используются такие инструменты контейнеризации, как Docker, Podman, Kubernetes и другие, обеспечивающие условия работы среды выполнения. Однако, не все знают, что указанные инструменты не абсолютно независимы, а используют для своей работы устроенные в ядро ОС Linux средства контейнеризации, в частности, Namespaces и Cgroup.Именно они позволяют работать с контейнерами, сравнимыми с облегченными виртуальными машинами. Прямое использование устроенных средств контейнеризации позволяет создать изолированную среду для запуска и выполнения любого процесса, в частности задачи администрирования. Linux. Рассмотрим методы создания и управления изолированными Runtime-средами с помощью устроенных средств ядра Linux.
Общие сведения
Что такое контейнеры на самом деле
Контейнеры являются одним из основных механизмов виртуализации среды выполнения приложений Runtime, развившийся как результат поиска эффективных решений для оптимизации работы направления DevOps
Запрос на поиск методов виртуализации всегда был связан с необходимостью оптимизации ресурсных затрат – машинных и финансовых. В настоящее время можно выделить три базовых типа организации Runtime среды – физический (Traditional), виртуальный (Virtualized) и контейнерный (Container) (см. Мал. 1).
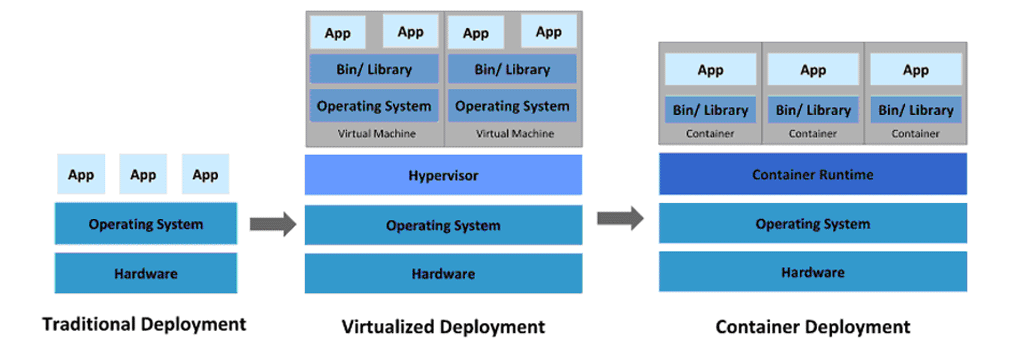
Риунок 1. Базовые типы организации Runtime среды.
Для первого, физического типа отсутствует какая-либо виртуализация и потому ресурсные затраты здесь максимальны. Примером применения может служить выделенный физический сервер (Dedicated Server) для обеспечения потребностей хостинга очень ценное и неэффективное решение в современных условиях для большинства задач
Виртуальный тип основан на использовании так называемых виртуальных машин. VM (Virtual Machine) – изолированного псевдо компьютера с отдельной ОС и собственными ресурсами. Виртуализация обеспечивается на аппаратном уровне. Машины образуются на базе промежуточного слоя – Hypervisorа (Hypervisor), который изолирует их от ОС и железа физической машины. Преимуществами использования технологии является экономия ресурсов по сравнению с физическим типом и возможность запуска на каждой из ВМ любой ОС. Недостатки – малая плотность размещения ВМ в пределах одного компьютера и большая инерционность (время запуска измеряется несколькими секундами). Примеры реализации – Xen, KVM(Kernel-based Virtual Machine).
Контейнерная среда выполнения функционирует на базе созданных в Container Runtime отдельных контейнеров для запуска изолированных задач Оно имеет много общих черт с ВМ, однако в отличие от последнего виртуализация здесь обеспечивается на уровне ОС – все контейнеры запускаются в пределах одного виртуального пространства на базе единого Linux-ядра. По сути, контейнеры представляют собой отдельные процессы с собственным пространством имен. Достоинства – большая плотность размещения, малая инерционность (время запуска в пределах нескольких мс), динамичность выделения и потребления ресурсов. В результате на одной физической машине может быть запущено гораздо больше приложений, чем в предыдущих двух типах. Runtime-пространства. Недостатки – повышенное внимание к вопросам безопасности и необходимость использования только одного Linux-дистрибутивов для всех контейнеров. Примеры реализации – FreeBSD jail, Solaris Containers, Linux-Vserver, OpenVZ, Docker.
История появления изолированных контейнерных сред выполнения
Runtime-пространство на основе контейнеров появилось гораздо раньше, чем его современные аналоги – Docker и Kubernetes.
Одной из первых платформ виртуализации контейнерного типа стала OpenVZ компании Parallels, Inc, первая версия которой увидела свет еще в 2005 году. Сейчас она является основой системы Virtuozzo, котораяшироко используется хостинг-компаниями для создания виртуальной среды для работы виртуальных частных серверов VPS (Virtual Private Servers)). По данным разработчиков, такие серверы обеспечивают производительность работы на том же уровне, что и обычные. Linux-серверы – падение составляет всего 2-3 %.
Подсистема контейнеризации LXC (Linux Containers) одной из французских компаний также рассчитана на работу с отдельными экземплярами операционной системы для каждого контейнера на базе единого ядра. Linux. Ее появление датируется началом августа 2008 года. Она была использована для организации работы сервиса Heroku – одного из первых в мире облачных PaaS-площадок. Первые версии платформы Docker опирались именно на нее, пока не перешли на собственные библиотеки.
OpenVZ и LXCиспользуют возможности устроенных средств контейнеризации. Именно это обеспечило их успех и позволило развиваться и дальше. Технологии Containers Solaris, Linux-Vserver и FreeBSD jail, также используют внутренние средства Linux для организации пространства выполнения программ контейнерного типа
Что такое namespaces
Как уже отмечалось, функционирование Container Runtime-пространство платформ контейнеризации стало возможным благодаря наличию устроенных механизмов ядра Linux. Одним из них является пространство имен Namespaces. Его основное предназначение – обеспечить изолированное использование ресурсов процессами. Реализуется это путем создания отдельных экземпляров системных ресурсов для каждого процесса.
Namespaces отсутствовал в первых версиях ядра, а был введен, начиная с версии 2.6.29. Его разработка длилась более десяти лет и была завершена в феврале 2013 с окончанием разработки одного из его видов – пространства имен пользователя. Завершенный вариант Namespaces был реализован в Linux-ядра версии 3.18.
Используется для платформ контейнеризации, изоляции сетевых ресурсов, тестирования ядра и нового программного обеспечения.
Види namespaces
Наличие разных типов системных ресурсов обусловило распределение пространства имен на разные виды. В настоящее время поддерживается шесть видов Namespaces:
-
mnt (точки монтирования);
-
net (сетевой стек);
-
pid (процессы);
-
uts (имя хоста);
-
ipc (System V IPC);
-
user (UID).
Mnt – позволяет изолировать файловые системы, то есть каждый процесс будет иметь «собственные» точки монтирования, недоступные другим процессам. Укажем на некоторые особенности организации указанного вида пространства:
-
При создании нового пространства все предварительные монтировки будут доступны для просмотра;
-
С момента создания пространства все операции монтирования/размонтирования становятся скрытыми для всех других процессов;
-
Операции монтажа / размонтирования, выполнены в глобальном пространстве имен, будут доступны для просмотра в новом пространстве.
Net - обеспечивает изоляцию сетевых ресурсов для каждого процесса. По логике является отдельной копией сетевого стека с собственными таблицами. АРП, сетевыми устройствами, SNMP-статистикой,/procfs и /sysfs записями, сокетами и правилами фаервола.
Особенности организации для текущего момента времени:
-
Сетевое устройство принадлежит единому Namespaces;
-
Выходной сетевой Net-пространство объединяет в себе все физические устройства, loopback-устройство, сетевые таблицы и т.п.;
-
Сокет принадлежит единому пространству имен;
-
Каждый новый Net-пространство имеет в своем составе только loopback-устройство.
Pid – обеспечивает изоляцию идентификаторов процессов. Имеет следующие особенности организации:
-
Процессы в разных Pid -пространствах могут иметь одинаковые идентификаторы;
-
Первый процесс в новом Pid-пространства будет иметь идентификатор под номером 1;
-
При закрытии любого процесса, для всех его «потомков» будет установлен «родительский» процесс, для которого Pid=1;
-
Процесс с Pid=1 неожиданно завершить с помощью сигнала SIGKILL;
-
Пространство может иметь до 32-х уровней вложенности.
Uts (Unix Time-Sharing) – изолирует сведенияо хосте и домене позволяет каждому изолированному процессу иметь собственные значения соответствующих параметров. Предоставляет возможность получить информацию о системе с помощью команд имя хоста да безымянный.
IPC (Inter-Process Communication) – Обеспечивает изоляцию способов взаимодействия между отдельными процессами, к которым, в частности, относятся: очереди сообщений, общая память и т.д. Организация пространства подчиняется тем же правилам, что и для Uts-простора.
User - позволяет процессам иметь в едином пространстве имен собственные значения идентификаторов UID и GID. Это, в частности, позволяет не root пользователю создавать процессы, в которых он будет иметь права root.
API namespaces
Для возможности работы с Namespaces был создан ряд инструментов, к которым относятся системные вызовы и шесть флажков CLONE_NEW..., использующиеся в системных вызовах в качестве дополнительных опций для формирования пространства имен определенной конфигурации.
APINamespaces включает три системных вызова:
clone() – создает новый процесс вместе с пространством имен посредством операции клонирования. Может обеспечить только общий доступ к ресурсам для всех процессов.
unshare() – создает новое пространство имен и подсоединяет к нему вызываемый процесс. Он отменяет установленный по умолчанию общий доступ к ресурсам. Его использование позволяет разделить между процессами пространство имен без необходимости применения операции клонирования, что усложнило бы этот процесс и сделало бы его более ресурсозатратным.
setns() – подключает к Namespaces вызываемый процесс.
Дополнительно используются функции fork() и exit() длясоздание и завершение процессов.
Флажки для каждого из видов Namespaces:
CLONE_NEWNS CLONE_NEWNET CLONE_NEWIPC CLONE_NEWPID CLONE_NEWUTS CLONE_NEWUSER
Каждому пространству при его создании присваивается уникальный номер inode. Закрытие Namespaces происходит только после закрытия всех процессов при условии, если его inode не содержит какой-либо из функций.
Примеры работы с Namespaces
При создании новых процессов все они по умолчанию будут прилагаться к уже существующим пространствам имен каждого вида. Для того чтобы изменить ситуацию, необходимо воспользоваться средствами создания нового Namespaces для определенного процесса. Но для этого нужно знать его PID. Его можно найти с помощью утилиты htop:
$ htop
Продемонстрируем смену UTS-пространства имен для копии процесса bash. Сначала пересмотрим все Namespaces, которым принадлежит процесс Они выводятся в виде файлов в каталоге /proc/<pid>/ns для процесса с указанным значением PID. Для bash значение pid выражается через символы $$.
Введем в терминале:
$ ls -l /proc/$$/ns
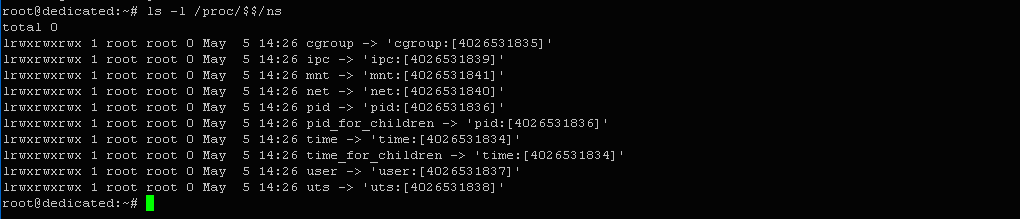
Выход:
lrwxrwxrwx 1 root root 0 May 5 14:26 cgroup -> 'cgroup:[4026531835]'
lrwxrwxrwx 1 root root 0 May 5 14:26 ipc -> 'ipc:[4026531839]' lrwxrwxrwx 1 root root 0 May 5 14:26 mnt -> 'mnt:[4026531841]' lrwxrwxrwx 1 root root 0 May 5 14:26 net -> 'net:[4026531840]' lrwxrwxrwx 1 root root 0 May 5 14:26 pid -> 'pid:[4026531836]' lrwxrwxrwx 1 root root 0 May 5 14:26 pid_for_children -> 'pid:[4026531836]' lrwxrwxrwx 1 root root 0 May 5 14:26 time -> 'time:[4026531834]' lrwxrwxrwx 1 root root 0 May 5 14:26 time_for_children -> 'time:[4026531834]' lrwxrwxrwx 1 root root 0 May 5 14:26 user -> 'user:[4026531837]' lrwxrwxrwx 1 root root 0 May 5 14:26 uts -> 'uts:[4026531838]'
Откроем второй терминал и проверим, какие Namespaces выделяются:
$ ls -l /proc/$$/ns

Можно убедиться, что выделяются те же пространства имен.
Теперь создадим отдельный UTS-пространство имен для копии процесса bash. Для этого введем:
$ sudo unshare -u bash

Проверим номера Namespaces:
$ ls -l /proc/$$/ns
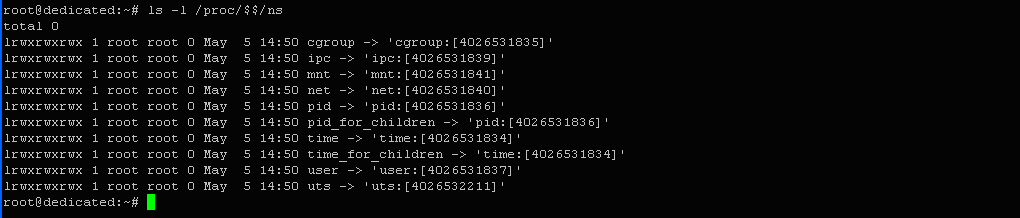
Выход:
lrwxrwxrwx 1 root root 0 May 5 14:50 cgroup -> 'cgroup:[4026531835]' .............................................................................................. lrwxrwxrwx 1 root root 0 May 5 14:50 uts -> 'uts:[4026532211]'
Можно убедиться, что пространство UTS изменился, а все остальные остались те же. Это говорит о том, что копия процесса bash выполняется в новом UTS-пространстве. Теперь у нас есть возможность изменить имя хоста во втором терминале, а в первом оно останется без изменений.
Проверим это с помощью команды смены названия хоста:
$ hostname newdedicated

Выясним текущее имя хоста:
$ hostname

Выход: newdedicated
В первом терминале та же команда даст другой результат:
$ hostname

Выход: dedicated
Так же мы можем создать изолированный PID-пространство для выполнения любого процесса.
Например, запустим команду, которая создаст PID-пространство для выполнения программы для вывода информации о текущем процессе.
Введем в терминале:
$ sudo unshare --fork --pid --mount-proc readlink /proc/self
Здесь опция --fork - обеспечивает выполнение команды в дочернем процессе; параметр --mount-proc – создает Namespaces для монтирования и одновременно монтирует файловую систему proc;утилита readlink – выводит системную информацию о процессе, содержащейся в процесс.
ФОТО 10
Выход: "1". Это значит, что в новом пространстве имен процесс имеет PID = 1.
После завершения выполнения программы readlink, новое пространство имен будет автоматически удалено.
Что такое Cgroups (control groups)
Это подсистема управления ресурсами (учет и отслеживание), предоставляющая общую структуру группирования процессов в соответствии с существующими ограничениями. Контролируются такие ресурсы, как ЦБ, память, сеть и т.д. Основанная на механизме «bean counters» с OpenVZ. Впервые появилась в Linux-ядра версии 2.6.24.
Подсистема для работы не требует системного вызова, а использует виртуальную файловую систему. VFS или cgroupfs. Это означает, что все ее действия выполняются через операции файловой системы – запись/чтение файлов, монтирование/размонтирование объектов, создание/удаление каталогов и т.п..
Для начала работы с группы необходимо смонтировать VFS. Как и любая другая файловая система VFS может быть смонтирована с использованием любого пути в файловой системе, но системная служба Systemd использует путь /sys/fs/cgroup.
Cgroups имеет одиннадцать контроллеров, которые можно подключить при монтаже с помощью параметра - о.
Основные из контроллеров:
-
Memory – устанавливает ограничения на использование ОП и Менять;
-
CPU – контролирует выделение процессорного времени;
-
PIDs – устанавливает ограничения на количество процессов в группе;
-
IO – регулирует ввод-вывод для блочных устройств;
-
Devices – ограничивает доступ к физическим устройств.
Пример:
$ mount -t cgroup –o pids нет /sys/fs/cgroup/pids
Здесь монтируется файловая система cgroupfs с использованием контроллера PIDs.
Развертывание на сервере
Для демонстрации некоторых возможностей по управлению ресурсами установим на VPS-сервер под управлением ОС Debian 12, механизм cgroup.
Обновляем индекс пакетов нашей системы:
$ sudo apt update
Устанавливаем пакет libcgroup-dev:
$ sudo apt установить libcgroup-dev
Выход:
Setting up libcgroup2:amd64 (2.0.2-2) Setting up libcgroup-dev:amd64 (2.0.2-2)
Итак, контрольная группа версии v2развернуто. Можно приступать к работе с задачами.
Примеры ограничения CPU и памяти
Сконфигурируем механизм контрольная группа в ручном режиме через иерархию sysfs.
Создадим директорию для группы задач с именем test_group:
$ sudo mkdir /sys/fs/cgroup/test_group

Установим предел использования памяти в 10 Mb для всех задач созданной группы:
$ echo $((10*1024*1024)) | sudo tee /sys/fs/cgroup/test_group/memory.max

Ограничим использование процессорных ресурсов до 10 процентов:
$ echo "10000 100000" | sudo тройник /sys/fs/cgroup/test_group/cpu.max
Здесь 10000 – квота в мс.

Добавим текущую задачу (интерпретатор bash) в нашу группу:
$ echo $$ | sudo tee /sys/fs/cgroup/test_group/cgroup.procs

После этого все запущены в bash команды будут попадать в список наших задач, для которых установлены ограничения.
Создание изолированной Runtime-среды
После установления ограничений остается только настроить механизм изоляции между задачами.
Как уже отмечалось, обеспечить создание отдельных пространств имен для каждого из процессов можно только с помощью утилиты. unshare, запущенной с соответствующими параметрами.
Команда будет выглядеть следующим образом:
$ sudo unshare --fork --pid --mount --uts --ipc --net --user --map-root-user --mount-proc /proc /bin/bash
Здесь опция --fork - создает копию процесса для нового NamNamespaces для root-пользователя;--mount-proc – монтирует //proc в созданном Mount-пространстве.
После выполнения команды изолированная среда будет готова к использованию. По своим характеристикам оно будет мало чем отличаться от Container Runtime известных систем контейнеризации
Подписывайтесь на наш телеграмм-канал https://t.me/freehostua, чтобы быть в курсе новых полезных материалов
Смотрите наш канал Youtube на https://www.youtube.com/freehostua.
Мы в чем ошиблись, или что-то пропустили?
Напишите об этом в комментариях, мы с удовольствием ответим и обсуждаем Ваши замечания и предложения.
|
Дата: 07.05.2025 Автор: Александр Ровник
|
|
Авторам статьи важно Ваше мнение. Будем рады его обсудить с Вами:
comments powered by Disqus