


Мы уверенны что среди наших клиентов, есть много профессионалов IT, работающих над интересными проектами. Если у Вас возникает желание рассказать о них, Вы можете разместить статью в нашем блоге. А чтоб было интересней, мы сделали конкурс статей, каждый месяц три победителя будут получать призы.
Статья также доступна на украинском (перейти к просмотру).

Содержание:
- Ключевые метрики
- Инструменты
- Мониторинг дисков с помощью Zabbix
- Когда менять диск
- FREEhost.UA помогает не пропустить проблему с диском
Во время активной и/или длительной эксплуатации дисковых носителей обычно накапливаются незначительные повреждения в виде bad-секторов или ошибок записи данных, что может в любой момент времени привести к выходу из строя и потере данных. Встроенная система SMART-контроль сама по себе не обеспечивает информирование о критическом состоянии диска, а лишь осуществляет накопление значений параметров, отражающих его состояние. Задача инструментов мониторинга прежде всего состоит в том, чтобы «вытащить» эти данные и на их основании вовремя сообщить пользователю об опасности. Но для этого нужно знать эти инструменты и уметь их настраивать в соответствии со своими потребностями.
Ключевые метрики
Технология SMART (Self-Monitoring, Analysis and Reporting Technology) предусматривает наличие группы метрик или атрибутов для каждого из поддерживающих ее носителей. Это устройства, работающие через интерфейсы ATA и SATA, поскольку технология — часть указанных протоколов.
Технология также имеет аналог для NVMe-SSD дисков и может работать с некоторыми типами флэш-накопителей, поддерживающих спецификацию SAT (трансляция SCSI-ATA), что делает ее достаточно универсальной.
Объясним значение наиболее употребляемых SMART-атрибутов для разных типов накопителей:
Жесткий диск (SATA/SAS)
Reallocated_Sector_Ct – Сохраняет количество bad-секторов, успешно перераспределенных;
Current_Pending_Sector – Сохраняет количество нестабильных секторов, находящихся в состоянии ожидания перераспределения;
Offline_Uncorrectable – фиксирует количество секторов, которые дисковый носитель не смог восстановить при выполнении последней операции по восстановлению данных;
UDMA_CRC_Error_Count – для диска, использующего интерфейс UltraDMA фиксирует количество ошибок передачи данных по внешнему интерфейсу в режиме UltraDMA. Повышенное значение может свидетельствовать о перекручивании кабеля и ненадежных контактах.
SSD (SATA)
Wear_Leveling_Count/Media_Wearout_Indicator/Percent_Lifetime_Used – отражает максимальное значение количества операций по очистке данных, выполняемое для одного блока флэш-памяти;
Reallocated_Sector_Ct – фиксирует количество операций по переназначению секторов. Процесс переназначения секторов или переназначение заключается в регистрации bad-секторов для дальнейшей обработки, и потому чем больше значение атрибута, тем хуже состояние поверхности накопителя;
Temperature_Celsius – текущая температура накопителя по Цельсию.
NVMe
Critical_Warning – вывод критических ошибок о состоянии накопителя;
Percentage_Used – оценивает процент использования ресурсов диска – чем меньше значение, тем выше износ;
Media_Errors – ошибки целостности данных;
Available_Spare – Текущее значение емкости резервной области для замены bad-секторов. При достижении некоторого минимального значения состояние носителя считается критическим;
Temperature_Celsius – текущая температура накопителя по Цельсию.
Инструменты
Существует несколько распространенных видов инструментов для работы с SMART-атрибутами в среде Linux/FreeBSD, применяемые в зависимости от типа накопителя и интерфейса его подключения:
-
Smartmontools: smartctl и smartd;
-
Nvme-cli (NVMe);
-
Обслуживание RAID-массивов.
Рассмотрим их более подробно.
Smartmontools: smartctl і smartd
Программный пакет Smartmontools применяется для мониторинга накопителей типа SATA/SAS и присутствует в репозиториях большинства дистрибутивов ОС Linux. Команды его установки для разных дистрибутивов выглядят следующим образом:
Debian/Ubuntu
$ apt update && apt install -y smartmontools'
FreeBSD
$ pkg install smartmontools
Пакет имеет два основных инструмента для работы с ним: smartctl (команда терминала) и smartd (даэмон), позволяющий автоматизировать тестирование дисковых носителей.
Приведем последовательность действий для получения первоначальной информации о состоянии носителя и доступных значений SMART-атрибутов на примере дистрибутива Debian/Ubuntu.
Вывести список всех доступных на компьютере накопителей:

получили вывод, включая логическую структуру, чтобы вывести только устройства модифицируемую команду:
~# lsblk | grep '^[a-zA-Z]'| grep disk sda 8:0 0 223.6G 0 disk sdb 8:16 0 223.6G 0 disk sdc 8:32 0 3.6T 0 disk sdd 8:48 0 3.6T 0 disk
Просмотрите основную техническую информацию о выбранном диске и убедитесь, что механизм SMART поддерживается системой и включен:
$ sudo smartctl -i /dev/sda smartctl 7.4 2024-10-15 r5620 [x86_64-linux-6.17.2-1-pve] (local build) Copyright (C) 2002-23, Bruce Allen, Christian Franke, www.smartmontools.org === START OF INFORMATION SECTION === Model Family: Intel 730 and DC S35x0/3610/3700 Series SSDs Device Model: INTEL SSDSC2BB240G4 Serial Number: PHWL4476005Z240NGN LU WWN Device Id: 5 5cd2e4 04c456a3c Firmware Version: D2012370 User Capacity: 240,057,409,536 bytes [240 GB] Sector Sizes: 512 bytes logical, 4096 bytes physical Rotation Rate: Solid State Device Form Factor: 2.5 inches TRIM Command: Available, deterministic, zeroed Device is: In smartctl database 7.3/5528 ATA Version is: ACS-2 T13/2015-D revision 3 SATA Version is: SATA 2.6, 6.0 Gb/s (current: 3.0 Gb/s) Local Time is: Fri Nov 21 12:12:35 2025 EET SMART support is: Available - device has SMART capability. SMART support is: Enabled
В данном случае механизм SMART включен. Если бы это было не так, включить его можно с помощью следующей команды:
$ sudo smartctl -s on /dev/sda
Выключить при необходимости командой:
$ sudo smartctl -s off /dev/sd
Проверить общее состояние носителя:
$ sudo smartctl -H /dev/sda
=== START OF READ SMART DATA SECTION ===
SMART overall-health self-assessment test result: PASSED
Результат теста (PASSED) говорит о том, что диск в норме.
Отобразить значения всех доступных SMART-атрибутов для sda1:
$ sudo smartctl -A /dev/sda smartctl 7.4 2024-10-15 r5620 [x86_64-linux-6.17.2-1-pve] (local build) Copyright (C) 2002-23, Bruce Allen, Christian Franke, www.smartmontools.org === START OF READ SMART DATA SECTION === SMART Attributes Data Structure revision number: 1 Vendor Specific SMART Attributes with Thresholds: ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE 5 Reallocated_Sector_Ct 0x0032 100 100 000 Old_age Always - 0 9 Power_On_Hours 0x0032 100 100 000 Old_age Always - 92494 12 Power_Cycle_Count 0x0032 100 100 000 Old_age Always - 38 170 Available_Reservd_Space 0x0033 100 100 010 Pre-fail Always - 0 171 Program_Fail_Count 0x0032 100 100 000 Old_age Always - 0 172 Erase_Fail_Count 0x0032 100 100 000 Old_age Always - 0 174 Unsafe_Shutdown_Count 0x0032 100 100 000 Old_age Always - 24 175 Power_Loss_Cap_Test 0x0033 100 100 010 Pre-fail Always - 642 (548 2701) 183 SATA_Downshift_Count 0x0032 100 100 000 Old_age Always - 0 184 End-to-End_Error 0x0033 100 100 090 Pre-fail Always - 0 187 Reported_Uncorrect 0x0032 100 100 000 Old_age Always - 0 190 Temperature_Case 0x0022 088 081 000 Old_age Always - 12 (Min/Max 10/19) 192 Unsafe_Shutdown_Count 0x0032 100 100 000 Old_age Always - 24 194 Temperature_Internal 0x0022 100 100 000 Old_age Always - 21 197 Current_Pending_Sector 0x0032 100 100 000 Old_age Always - 0 199 CRC_Error_Count 0x003e 100 100 000 Old_age Always - 0 225 Host_Writes_32MiB 0x0032 100 100 000 Old_age Always - 2075149 226 Workld_Media_Wear_Indic 0x0032 100 100 000 Old_age Always - 22221 227 Workld_Host_Reads_Perc 0x0032 100 100 000 Old_age Always - 54 228 Workload_Minutes 0x0032 100 100 000 Old_age Always - 5549417 232 Available_Reservd_Space 0x0033 100 100 010 Pre-fail Always - 0 233 Media_Wearout_Indicator 0x0032 079 079 000 Old_age Always - 0 234 Thermal_Throttle 0x0032 100 100 000 Old_age Always - 0/0 241 Host_Writes_32MiB 0x0032 100 100 000 Old_age Always - 2075149 242 Host_Reads_32MiB 0x0032 100 100 000 Old_age Always - 2459155
Для FreeBSD аналогичная команда будет выглядеть так:
$ smartctl -a /dev/ada0
Для получения более полной информации по атрибутам можно воспользоваться командой:
$ sudo smartctl --all /dev/sda
После оценки полученных значений атрибутов сделать выводы о состоянии диска и при необходимости запустить сокращенное (Short) самотестирование устройства:
$ sudo smartctl -t short /dev/sda === START OF OFFLINE IMMEDIATE AND SELF-TEST SECTION === Sending command: "Execute SMART Short self-test routine immediately in off-line mode". Drive command "Execute SMART Short self-test routine immediately in off-line mode" successful. Testing has begun. Please wait 2 minutes for test to complete. Test will complete after Tue Nov 18 15:33:05 2025
Подождать несколько минут и получить результаты тестирования с помощью команды:
$ sudo smartctl -l selftest /dev/sda === START OF READ SMART DATA SECTION === SMART Self-test log structure revision number 1 Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error # 1 Short offline Completed without error 00% 32685 -
В зависимости от результатов сокращенного тестирования при необходимости можно запустить длительное расширенное самотестирование (Long/extended), которое проведет более полный анализ поверхности носителя. Это можно сделать с помощью команды:
$ sudo smartctl -t long /dev/sda
Продолжительность тестирования может занять несколько часов в зависимости от скорости работы носителя и его емкости. Проверить результаты можно с помощью команды:
$ sudo smartctl -c /dev/sda
Настроить автоматический SMART-мониторингсостояния накопителя в режиме smartd, для чего включить нужные типы носителей в файл /etc/smartd.conf:
$ sudo nano /etc/smartd.conf # First two SCSI disks. This will monitor everything that smartd can # monitor. Start extended self-tests Wednesdays between 6-7pm and # Sundays between 1-2 am /dev/sda -d scsi -s L/../../3/18
В этом случае самотестирование sda-диск будет осуществляться каждую среду с 18 до 19 часов и каждое воскресенье с 1 до 2 часов.
Завершить настройки командами:
$ sudo systemctl enable smartd
$ sudo systemctl start smartd
Nvme-cli (NVMe)
В настоящее время отсутствует поддержка пакетом Smartmontools файловых хранилищ на базе NVMe, то есть, нет универсального средства мониторинга всех существующих типов носителей. И потому для работы с NVMe-SSd-дисками обычно используется пакет Nvme-cli, специально разработанный для Linux-систем. Он использует IOCTL, которые определяются основным драйвером ядра и применяется для работы с хранилищами NVMe в терминальном режиме.
Общий синтаксис команд утилиты выглядит следующим образом:
nvme <команда> <устройство> [<аргументы>]
Здесь<устройство> – обязательный параметр, который может быть символьным (/dev/nvmeX) или блочным устройством (/dev/nvmeXn1) пространства имен.
Просмотреть список всех команд и их синтаксис можно с помощью команды терминала:
$ nvme help
Установить пакет:
$ sudo apt install nvme-cli
Получить данные об установленных в системе устройствах NVMe:
$ nvme list Node SN Model Version Namespace Usage Format FW Rev ---------------- -------------------- ---------------------------------------- -------- --------- -------------------------- ---------------- -------- /dev/nvme0n1 S3DETCNHB01582C Samsung SSD 960 PRO 1TB 1.3 1 677.52 GB / 1.03 TB512 B + 0 B 1M3QZXP8
Вывести для устройства nvme0 страницу журнала SMART в удобном для восприятия человеком формате:
$ nvme smart-log /dev/nvme0 Smart Log for NVME device:nvme0 namespace-id:ffffffff critical_warning : 0 temperature : 33 C available_spare : 100% available_spare_threshold : 9% percentage_used : 1% data_units_read : 3,531,278 data_units_written : 9,051,597 host_read_commands : 88,921,356 host_write_commands : 126,562,383 controller_busy_time : 312 power_cycles : 12 power_on_hours : 19 unsafe_shutdowns : 7 media_errors : 0 num_err_log_entries : 2 Warning Temperature Time : 0 Critical Composite Temperature Time : 0 Temperature Sensor 1 : 33 C Temperature Sensor 2 : 42 C Temperature Sensor 3 : 0 C
Вывести в файл необработанный журнал SMART для устройства nvme0:
$ nvme smart-log /dev/nvme0 --raw-binary > smart_log.raw
Обслуживание RAID-массивов
Технология RAID (Redundant Array of Independent Disks) обеспечивает избыточный массив независимых друг от друга носителей для их объединения в одно хранилище данных. Они могут быть реализованы на программном (виртуализированном) или аппаратном уровне.
Для мониторинга работы RAID-массивов можно использовать различные средства в зависимости от типа RAID.
Для контроля SMART-параметров дисков RAID-массива можно использовать те же команды утилиты Smartmontools, что и в случае их единичного использования.
Debian/Ubuntu
$ sudo smartctl -A /dev/sda
Вывести текущее состояние всех зарегистрированных в системе RAID-массивов можно с помощью команды:
$ cat /proc/mdstat
Личности
[raid1] md0 : активный raid1 sdb1[0] sdc1[1] 575532516 блоков супер 1.2 [2/2] [UU]
Команда вывела статус дисков (active); имя raid-устройства (md0); символьные имена дисков, входящих в состав устройства; имя созданного массива (raid1); количество носителей, работающих в массиве ([2/2] [UU]).
Иногда могут возникать сложности в получении значений SMART-атрибутов, если RAID-массив построен на аппаратном уровне. В таком случае следует использовать утилиты производителей оборудования, например, storcli, megacli или arcconf.
Вместе с тем, не следует игнорировать использование инструмента smartctl для проверки состояния носителей и создания восстановительных точек для быстрого восстановления данных.
Мониторинг дисков с помощью Zabbix
Система мониторинга статусов сетевых сервисов и компьютерного оборудования Zabbix соединила в себе возможности утилиты Smartmontools со своими технологическими решениями. Ее можно использовать для сбора значений SMART-параметров дисков разного типа: HDD, SSD, NVMe с включенной SMART-функцией.
Zabbix поддерживает два подхода к управлению SMART-атрибутами устройств:
-
С помощью пользовательских параметров (UserParameter);
-
С помощью механизма низкоуровневого обнаружения LLD (Low-Level Discovery).
Первый подход в основном использовался в первых версиях программы и имеет ряд недостатков, среди которых ручное управление элементами данных и другими сущностями, а также избыточные запуски smartctl с периодическим обращением к контроллерам накопителей, что снижает эффективность работы программы.
Второй подход основан на правилах обнаружения LLD и обеспечивает автоматическое создание элементов данных, триггеров и графиков любого типа сущностей с автоматическим запуском мониторинга системы. Пользователь имеет возможность определить собственные типы обнаружения устройств на основе JSON-файл. Подход более эффективен, упрощает настройки, и поэтому целесообразно использовать именно его.
В git-репозитории разработчиков присутствует шаблон SMART от Zabbix агент 2 с реализацией SMART-функция для последней версии Zabbix-агента, построенный на базе LLD и сконфигурирован на автоматическое обнаружение всех HDD, SSD, NVMe накопителей, а также считывание всех атрибутов, специфичных для поставщика оборудования. Его применение не требует внешних скриптов и потому очень удобно для практического использования. Просмотреть информацию о совместном использовании Zabbix-агента с указанным шаблоном можно здесь.
Приведем последовательность действий для практического использования инструмента Zabbix для мониторинга всех типов накопителей целевого хоста:
-
Установить сервер Zabbix версии 6.2+. Загрузить установочный файл можно с сайта разработчиков.
-
Установить агент Zabbixagent 2 на целевой хост.
-
Установить пакет Smartmontools версии 7.1+ на целевой хост.
-
Предоставить агенту Zabbixagent 2 права суперпользователя для запуска команд smartctl. Для этого следует добавить в файл /etc/sudoers целевого хоста следующую строчку: zabbix ALL=(ALL) NOPASSWD:/usr/sbin/smartctl.
-
Проверить статус Zabbix-агента на хосте. Это можно сделать с помощью команды:$ service zabbix-agent2 status.
-
Подключить шаблон SMART от Zabbixagent 2 к целевому хосту. Это можно сделать прямо из интерфейса Zabbix, загрузив шаблон с сайта разработчиков. Если все хорошо, страница настроек хоста в Zabbix будет выглядеть так, как показано на скриншоте ниже.
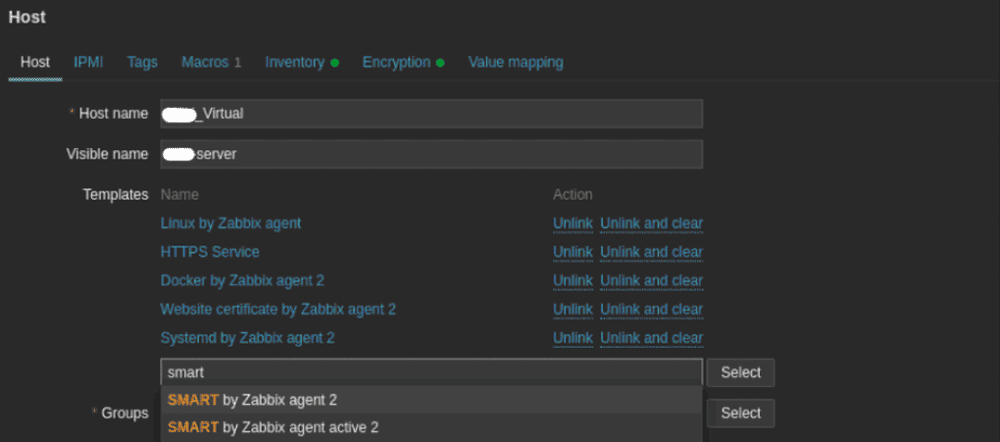
-
Через 5-6 часов после выполнения указанных настроек проверить результаты мониторинга в главном окне программы (см. скриншот).
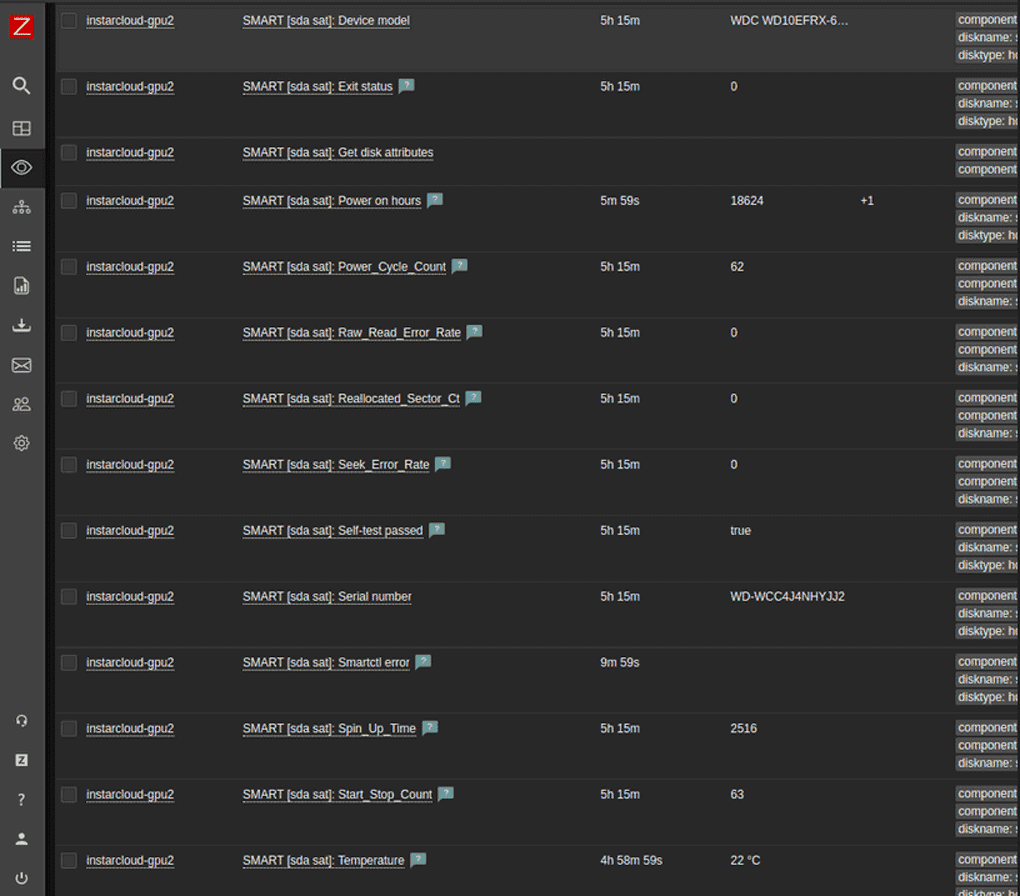
Полная документация по продукту находится здесь.
Когда менять диск
- Одразу: Current_Pending_Sector > 0, Offline_Uncorrectable > 0, critic_warning != 0, поява media_errors.
- Планово: стабильный рост Reallocated_Sector_Ct, износ SSD/NVMe ≥80%, повторные UDMA_CRC (после проверки кабелей/порта).
FREEhost.UA помогает не пропустить проблему с диском
Мы понимаем, что не каждый администратор ежедневно изучает SMART-отчёты. Поэтому на серверах, которые клиенты арендуют у FREEhost.UA, мы настраиваем небольшой сервис, который контролирует состояние физических дисков и автоматически уведомляет наших инженеров при обнаружении потенциальных сбоев. Это позволяет заменять диск до отказа и избегать простоев.
Кроме того, мы рекомендуем клиентам придерживаться двух базовых правил: делайте резервные копии и используйте RAID. Это самая надёжная защита от потери данных в любой инфраструктуре.
Узнайте больше об аренде серверов в дата-центре FREEhost.UA.
Подписывайтесь на наш телеграмм-канал https://t.me/freehostua, чтобы быть в курсе новых полезных материалов
Смотрите наш канал Youtube на https://www.youtube.com/freehostua.
Мы в чем ошиблись, или что-то пропустили?
Напишите об этом в комментариях, мы с удовольствием ответим и обсудим Ваши замечания и предложения.
|
Дата: 27.11.2025 Автор: Александр Ровник
|
|
Авторам статьи важно Ваше мнение. Будем рады его обсудить с Вами:
comments powered by Disqus